Note
This page was generated from
MultiVI_tutorial.ipynb.
Interactive online version:
![]() .
Some tutorial content may look better in light mode.
.
Some tutorial content may look better in light mode.
Joint analysis of paired and unpaired multiomic data with MultiVI#
MultiVI is used for the joint analysis of scRNA and scATAC-seq datasets that were jointly profiled (multiomic / paired) and single-modality datasets (only scRNA or only scATAC). MultiVI uses the paired data as an anchor to align and merge the latent spaces learned from each individual modality.
This tutorial walks through how to read multiomic data, create a joint object with paired and unpaired data, set-up and train a MultiVI model, visualize the resulting latent space, and run differential analyses.
[ ]:
!pip install --quiet scvi-colab
from scvi_colab import install
install()
[1]:
import numpy as np
import scanpy as sc
import scvi
Data acquisition#
First we download a sample multiome dataset from 10X. We’ll use this throughout this tutorial. Importantly, MultiVI assumes that there are shared features between the datasets. This is trivial for gene expression datasets, which generally use the same set of genes as features. For ATAC-seq peaks, this is less trivial, and often requires preprocessing steps with other tools to get all datasets to use a shared set of peaks. That can be achieved with tools like SnapATAC, ArchR, and CellRanger in the case of 10X data.
Important
MultiVI requires the datasets to use shared features. scATAC-seq datasets need to be processed to use a shared set of peaks.
[ ]:
!wget https://cf.10xgenomics.com/samples/cell-arc/2.0.0/pbmc_unsorted_10k/pbmc_unsorted_10k_filtered_feature_bc_matrix.tar.gz
!sudo tar -xvf pbmc_unsorted_10k_filtered_feature_bc_matrix.tar.gz
!gunzip -f filtered_feature_bc_matrix/*.gz
[2]:
scvi.settings.seed = 420
%config InlineBackend.print_figure_kwargs={'facecolor' : "w"}
%config InlineBackend.figure_format='retina'
Global seed set to 0
Global seed set to 420
Data Processing#
Next, we’ll read the data into an Anndata object. We’ll then split the data to three datasets, and remove some modality-specific data from parts of the dataset, to demonstrate how MultIVI mixes multimodal and single-modal data. The data has 12012 cells, we’ll use 4004 for each dataset.
Reading the data into an AnnData object can be done with the read_10x_multiome function:
[3]:
# read multiomic data
adata = scvi.data.read_10x_multiome("filtered_feature_bc_matrix")
adata.var_names_make_unique()
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
We can now split the dataset to three datasets, and remove a modality from two of them, so we’ll have equal-sized (4004 cells in each) datasets with multiome, expression-only, and accessibility-only observations:
[4]:
# split to three datasets by modality (RNA, ATAC, Multiome), and corrupt data
# by remove some data to create single-modality data
n = 4004
adata_rna = adata[:n, adata.var.modality == "Gene Expression"].copy()
adata_paired = adata[n : 2 * n].copy()
adata_atac = adata[2 * n :, adata.var.modality == "Peaks"].copy()
We can then use the organize_multiome_anndatas function to orgnize these three datasets into a single Multiome dataset. This function sorts and orders the data from the multi-modal and modality-specific AnnDatas into a single AnnData (aligning the features, padding missing modalities with 0s, etc).
[5]:
# We can now use the organizing method from scvi to concatenate these anndata
adata_mvi = scvi.data.organize_multiome_anndatas(adata_paired, adata_rna, adata_atac)
Note that organize_multiome_anndatas adds an annotation to the cells to indicate which modality they originate from:
[6]:
adata_mvi.obs
[6]:
| batch_id | modality | |
|---|---|---|
| CCGCTAAAGGGCCATC_paired | 1 | paired |
| CCGCTAAAGTCTTGAA_paired | 1 | paired |
| CCGCTAAAGTTAGACC_paired | 1 | paired |
| CCGCTAAAGTTCCCAC_paired | 1 | paired |
| CCGCTAAAGTTTGCGG_paired | 1 | paired |
| ... | ... | ... |
| TTTGTTGGTACGCGCA_accessibility | 1 | accessibility |
| TTTGTTGGTATTTGCC_accessibility | 1 | accessibility |
| TTTGTTGGTGATTACG_accessibility | 1 | accessibility |
| TTTGTTGGTTTCAGGA_accessibility | 1 | accessibility |
| TTTGTTGGTTTCCACG_accessibility | 1 | accessibility |
12012 rows × 2 columns
Important
MultiVI requires the features to be ordered so that genes appear before genomic regions. This must be enforced by the user.
MultiVI requires the features to be ordered, such that genes appear before genomic regions. In this case this is already the case, but it’s always good to verify:
[7]:
adata_mvi = adata_mvi[:, adata_mvi.var["modality"].argsort()].copy()
adata_mvi.var
[7]:
| ID | modality | chr | start | end | |
|---|---|---|---|---|---|
| MIR1302-2HG | ENSG00000243485 | Gene Expression | chr1 | 29553 | 30267 |
| AL391261.2 | ENSG00000258847 | Gene Expression | chr14 | 66004522 | 66004523 |
| FUT8-AS1 | ENSG00000276116 | Gene Expression | chr14 | 65412689 | 65412690 |
| FUT8 | ENSG00000033170 | Gene Expression | chr14 | 65410591 | 65413008 |
| AL355076.2 | ENSG00000258760 | Gene Expression | chr14 | 65302679 | 65318790 |
| ... | ... | ... | ... | ... | ... |
| chr15:101277030-101277907 | chr15:101277030-101277907 | Peaks | chr15 | 101277030 | 101277907 |
| chr15:101257856-101258771 | chr15:101257856-101258771 | Peaks | chr15 | 101257856 | 101258771 |
| chr15:101251516-101252373 | chr15:101251516-101252373 | Peaks | chr15 | 101251516 | 101252373 |
| chr15:101397608-101398445 | chr15:101397608-101398445 | Peaks | chr15 | 101397608 | 101398445 |
| KI270713.1:36924-37836 | KI270713.1:36924-37836 | Peaks | KI270713.1 | 36924 | 37836 |
148458 rows × 5 columns
We also filter features to remove those that appear in fewer than 1% of the cells
[8]:
print(adata_mvi.shape)
sc.pp.filter_genes(adata_mvi, min_cells=int(adata_mvi.shape[0] * 0.01))
print(adata_mvi.shape)
(12012, 148458)
(12012, 80878)
Setup and Training MultiVI#
We can now set up and train the MultiVI model!
First, we need to setup the Anndata object using the setup_anndata function. At this point we specify any batch annotation that the model would account for. Importantly, the main batch annotation, specific by batch_key, should correspond to the modality of the cells.
Other batch annotations (e.g if there are multiple ATAC batches) should be provided using the categorical_covariate_keys.
The actual values of categorical covariates (include batch_key) are not important, as long as they are different for different samples. I.e it is not important to call the expression-only samples “expression”, as long as they are called something different than the multi-modal and accessibility-only samples.
Important
MultiVI requires the main batch annotation to correspond to the modality of the samples. Other batch annotation, such as in the case of multiple RNA-only batches, can be specified using categorical_covariate_keys.
[9]:
scvi.model.MULTIVI.setup_anndata(adata_mvi, batch_key="modality")
When creating the object, we need to specify how many of the features are genes, and how many are genomic regions. This is so MultiVI can determine the exact architecture for each modality.
[10]:
mvi = scvi.model.MULTIVI(
adata_mvi,
n_genes=(adata_mvi.var["modality"] == "Gene Expression").sum(),
n_regions=(adata_mvi.var["modality"] == "Peaks").sum(),
)
mvi.view_anndata_setup()
Anndata setup with scvi-tools version 0.15.0b0.
Setup via `MULTIVI.setup_anndata` with arguments:
{ │ 'layer': None, │ 'batch_key': 'modality', │ 'labels_key': None, │ 'size_factor_key': None, │ 'categorical_covariate_keys': None, │ 'continuous_covariate_keys': None }
Summary Statistics ┏━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━┓ ┃ Summary Stat Key ┃ Value ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━┩ │ n_cells │ 12012 │ │ n_vars │ 80878 │ │ n_batch │ 3 │ │ n_labels │ 1 │ │ n_extra_categorical_covs │ 0 │ │ n_extra_continuous_covs │ 0 │ └──────────────────────────┴───────┘
Data Registry ┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Registry Key ┃ scvi-tools Location ┃ ┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ X │ adata.X │ │ batch │ adata.obs['_scvi_batch'] │ │ labels │ adata.obs['_scvi_labels'] │ └──────────────┴───────────────────────────┘
batch State Registry ┏━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┓ ┃ Source Location ┃ Categories ┃ scvi-tools Encoding ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━┩ │ adata.obs['modality'] │ accessibility │ 0 │ │ │ expression │ 1 │ │ │ paired │ 2 │ └───────────────────────┴───────────────┴─────────────────────┘
labels State Registry ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┓ ┃ Source Location ┃ Categories ┃ scvi-tools Encoding ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━┩ │ adata.obs['_scvi_labels'] │ 0 │ 0 │ └───────────────────────────┴────────────┴─────────────────────┘
[11]:
mvi.train()
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2]
Epoch 1/500: 0%| | 0/500 [00:00<?, ?it/s]
/data/yosef2/users/jhong/miniconda3/envs/v15/lib/python3.9/site-packages/scvi/module/_multivae.py:567: UserWarning: The use of `x.T` on tensors of dimension other than 2 to reverse their shape is deprecated and it will throw an error in a future release. Consider `x.mT` to transpose batches of matricesor `x.permute(*torch.arange(x.ndim - 1, -1, -1))` to reverse the dimensions of a tensor. (Triggered internally at /opt/conda/conda-bld/pytorch_1645690191318/work/aten/src/ATen/native/TensorShape.cpp:2402.)
x = torch.where(mask_expr.T, x_expr.T, x_acc.T).T
/data/yosef2/users/jhong/miniconda3/envs/v15/lib/python3.9/site-packages/scvi/distributions/_negative_binomial.py:56: UserWarning: Specified kernel cache directory could not be created! This disables kernel caching. Specified directory is /home/eecs/jjhong922/.cache/torch/kernels. This warning will appear only once per process. (Triggered internally at /opt/conda/conda-bld/pytorch_1645690191318/work/aten/src/ATen/native/cuda/jit_utils.cpp:860.)
+ torch.lgamma(x + theta)
Epoch 244/500: 49%|████▉ | 244/500 [36:12<37:59, 8.90s/it, loss=6.68e+03, v_num=1]
Monitored metric elbo_validation did not improve in the last 45 records. Best score: 14214.882. Signaling Trainer to stop.
Save and Load MultiVI models#
Saving and loading models is similar to all other scvi-tools models, and is very straight forward:
[12]:
mvi.save("trained_multivi")
[14]:
mvi = scvi.model.MULTIVI.load("trained_multivi", adata=adata_mvi)
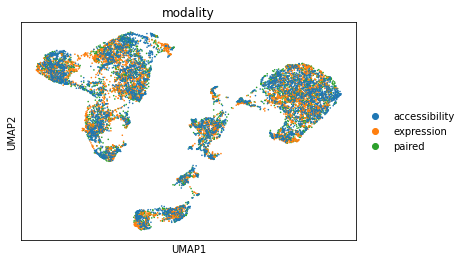
Extracting and visualizing the latent space#
We can now use the get_latent_representation to get the latent space from the trained model, and visualize it using scanpy functions:
[15]:
adata_mvi.obsm["MultiVI_latent"] = mvi.get_latent_representation()
sc.pp.neighbors(adata_mvi, use_rep="MultiVI_latent")
sc.tl.umap(adata_mvi, min_dist=0.2)
sc.pl.umap(adata_mvi, color="modality")
/data/yosef2/users/jhong/miniconda3/envs/v15/lib/python3.9/site-packages/anndata/_core/anndata.py:1228: FutureWarning: The `inplace` parameter in pandas.Categorical.reorder_categories is deprecated and will be removed in a future version. Reordering categories will always return a new Categorical object.
c.reorder_categories(natsorted(c.categories), inplace=True)
... storing 'modality' as categorical
/data/yosef2/users/jhong/miniconda3/envs/v15/lib/python3.9/site-packages/anndata/_core/anndata.py:1228: FutureWarning: The `inplace` parameter in pandas.Categorical.reorder_categories is deprecated and will be removed in a future version. Reordering categories will always return a new Categorical object.
c.reorder_categories(natsorted(c.categories), inplace=True)
... storing 'modality' as categorical
/data/yosef2/users/jhong/miniconda3/envs/v15/lib/python3.9/site-packages/anndata/_core/anndata.py:1228: FutureWarning: The `inplace` parameter in pandas.Categorical.reorder_categories is deprecated and will be removed in a future version. Reordering categories will always return a new Categorical object.
c.reorder_categories(natsorted(c.categories), inplace=True)
... storing 'chr' as categorical
Impute missing modalities#
In a well-mixed space, MultiVI can seamlessly impute the missing modalities for single-modality cells. First, imputing expression and accessibility is done with get_normalized_expression and get_accessibility_estimates, respectively.
We’ll demonstrate this by imputing gene expression for all cells in the dataset (including those that are ATAC-only cells):
[16]:
imputed_expression = mvi.get_normalized_expression()
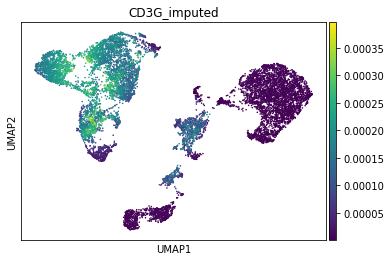
We can demonstrate this on some known marker genes:
First, T-cell marker CD3.
[21]:
gene_idx = np.where(adata_mvi.var.index == "CD3G")[0]
adata_mvi.obs["CD3G_imputed"] = imputed_expression.iloc[:, gene_idx]
sc.pl.umap(adata_mvi, color="CD3G_imputed")
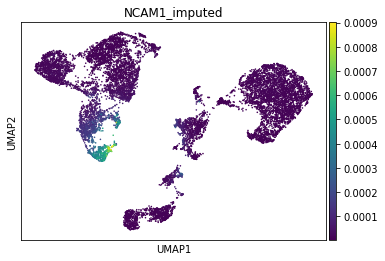
Next, NK-Cell marker gene NCAM1 (CD56):
[22]:
gene_idx = np.where(adata_mvi.var.index == "NCAM1")[0]
adata_mvi.obs["NCAM1_imputed"] = imputed_expression.iloc[:, gene_idx]
sc.pl.umap(adata_mvi, color="NCAM1_imputed")
Finally, B-Cell Marker CD19:
[23]:
gene_idx = np.where(adata_mvi.var.index == "CD19")[0]
adata_mvi.obs["CD19_imputed"] = imputed_expression.iloc[:, gene_idx]
sc.pl.umap(adata_mvi, color="CD19_imputed")
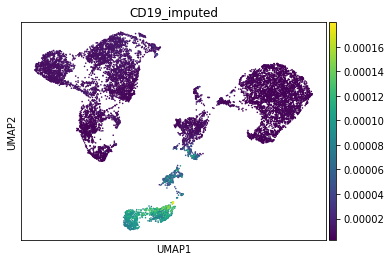
All three marker genes clearly identify their respective populations. Importantly, the imputed gene expression profiles are stable and consistent within that population, even though many of those cells only measured the ATAC profile of those cells.