9. Linearly decoded VAE¶
This notebook shows how to use the ‘linearly decoded VAE’ model which explicitly links latent variables of cells to genes.
The scVI package learns low-dimensional latent representations of cells which get mapped to parameters of probability distributions which can generate counts consistent to what is observed from data. In the standard VAE model of scVI these parameters for each gene and cell arise from applying neural networks to the latent variables. Neural networks are flexible and can represent non-linearities in the data. This comes at a price, there is no direct link between a latent variable dimension
and any potential set of genes which would covary across it.
The LDVAE model replaces the neural networks with linear functions. Now a higher value along a latent dimension will directly correspond to higher expression of the genes with high weights assigned to that dimension.
This leads to a generative model comparable to probabilistic PCA or factor analysis, but generates counts rather than real numbers. Using the framework of scVI also allows variational inference which scales to very large datasets and can make use of GPUs for additional speed.
This notebook demonstrates how to fit an LDVAE model to scRNA-seq data, plot the latent variables, and interpret which genes are linked to latent variables.
As an example, we use the PBMC 10K from 10x Genomics.
[1]:
# Cell left blank for testing purposes
Automated testing configuration
[2]:
import os
def allow_notebook_for_test():
print("Testing the ldvae notebook")
test_mode = False
save_path = "data/"
n_epochs_all = None
show_plot = True
if not test_mode:
save_path = "../../data"
data_path = os.path.join(save_path, "filtered_gene_bc_matrices/hg19/")
[3]:
import torch
from scvi.dataset import GeneExpressionDataset, Dataset10X
from scvi.models import LDVAE
from scvi.inference import UnsupervisedTrainer, Trainer
from scvi.inference.posterior import Posterior
import pandas as pd
import anndata
import scanpy as sc
import matplotlib.pyplot as plt
if not test_mode:
%matplotlib inline
[2019-11-08 08:29:48,883] INFO - scvi._settings | Added StreamHandler with custom formatter to 'scvi' logger.
/data/yosef2/users/adamgayoso/.pyenv/versions/scvi/lib/python3.7/site-packages/sklearn/utils/linear_assignment_.py:21: DeprecationWarning: The linear_assignment_ module is deprecated in 0.21 and will be removed from 0.23. Use scipy.optimize.linear_sum_assignment instead.
DeprecationWarning)
9.1. Initialization¶
[4]:
import torch
import numpy as np
from scvi import set_seed
# Setting seeds for reproducibility
set_seed(0)
[5]:
cells_dataset = Dataset10X(
dataset_name="pbmc_10k_protein_v3",
save_path=os.path.join(save_path, "10X"),
measurement_names_column=1,
dense=True,
)
[2019-11-08 08:29:54,093] INFO - scvi.dataset.dataset10X | Preprocessing dataset
[2019-11-08 08:30:28,302] INFO - scvi.dataset.dataset10X | Finished preprocessing dataset
[2019-11-08 08:30:30,214] INFO - scvi.dataset.dataset | Remapping batch_indices to [0,N]
[2019-11-08 08:30:30,216] INFO - scvi.dataset.dataset | Remapping labels to [0,N]
[2019-11-08 08:30:30,625] INFO - scvi.dataset.dataset | Computing the library size for the new data
[2019-11-08 08:30:31,031] INFO - scvi.dataset.dataset | Downsampled from 7865 to 7865 cells
9.2. Create and fit LDVAE model¶
First subsample 1,000 genes from the original data.
Then we initialize an LDVAE model and a Trainer for that model. Here we set the latent space to have 10 dimensions.
[6]:
cells_dataset.subsample_genes(1000)
[2019-11-08 08:30:36,992] INFO - scvi.dataset.dataset | Downsampling from 33538 to 1000 genes
[2019-11-08 08:30:37,081] INFO - scvi.dataset.dataset | Computing the library size for the new data
[2019-11-08 08:30:37,108] INFO - scvi.dataset.dataset | Filtering non-expressing cells.
[2019-11-08 08:30:37,144] INFO - scvi.dataset.dataset | Computing the library size for the new data
[2019-11-08 08:30:37,159] INFO - scvi.dataset.dataset | Downsampled from 7865 to 7865 cells
[7]:
vae = LDVAE(
cells_dataset.nb_genes,
n_batch=cells_dataset.n_batches,
n_latent=10,
n_layers_encoder=1,
n_hidden=128,
reconstruction_loss="nb",
latent_distribution="normal",
)
[8]:
trainer = UnsupervisedTrainer(vae,
cells_dataset,
frequency=1,
use_cuda=True,
n_epochs_kl_warmup=None
)
Now train the model using the trainer, and inspect the convergence.
[9]:
n_epochs = 250 if n_epochs_all is None else n_epochs_all
trainer.train(lr=5e-3, n_epochs=250)
training: 100%|██████████| 250/250 [03:03<00:00, 1.36it/s]
[10]:
if not test_mode:
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot(trainer.history['elbo_train_set'][10:])
ax.plot(trainer.history['elbo_test_set'][10:])
9.3. Extract and plot latent dimensions for cells¶
From the fitted model we extract the (mean) values for the latent dimensions. We store the values in the AnnData object for convenience.
[11]:
full = trainer.create_posterior(trainer.model, cells_dataset, indices=np.arange(len(cells_dataset)))
Z_hat = full.sequential().get_latent()[0]
adata = anndata.AnnData(cells_dataset.X)
[12]:
for i, z in enumerate(Z_hat.T):
adata.obs[f'Z_{i}'] = z
Now we can plot the latent dimension coordinates for each cell. A quick (albeit not complete) way to view these is to make a series of 2D scatter plots that cover all the dimensions. Since we are representing the cells by 10 dimensions, this leads to 5 scatter plots.
[13]:
fig = plt.figure(figsize=(12, 8))
for f in range(0, 9, 2):
plt.subplot(2, 3, int(f / 2) + 1)
plt.scatter(adata.obs[f'Z_{f}'], adata.obs[f'Z_{f + 1}'], marker='.', s=4, label='Cells')
plt.xlabel(f'Z_{f}')
plt.ylabel(f'Z_{f + 1}')
plt.subplot(2, 3, 6)
plt.scatter(adata.obs[f'Z_{f}'], adata.obs[f'Z_{f + 1}'], marker='.', label='Cells', s=4)
plt.scatter(adata.obs[f'Z_{f}'], adata.obs[f'Z_{f + 1}'], c='w', label=None)
plt.gca().set_frame_on(False)
plt.gca().axis('off')
lgd = plt.legend(scatterpoints=3, loc='upper left')
for handle in lgd.legendHandles:
handle.set_sizes([200])
plt.tight_layout()
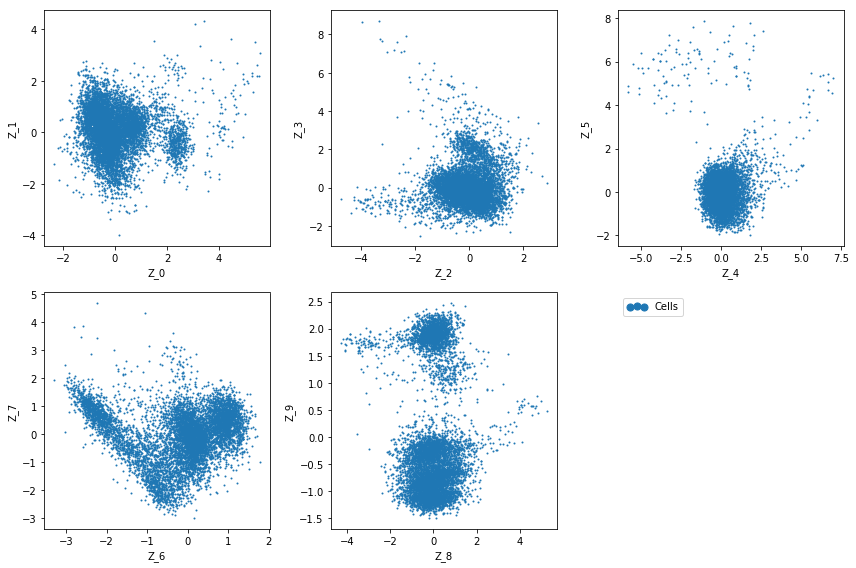
The question now is how does the latent dimensions link to genes?
For a given cell x, the expression of the gene g is proportional to x_g = w_(1, g) * z_1 + … + w_(10, g) * z_10. Moving from low values to high values in z_1 will mostly affect expression of genes with large w_(1, :) weights. We can extract these weights from the LDVAE model, and identify which genes have high weights for each latent dimension.
[14]:
loadings = vae.get_loadings()
loadings = \
pd.DataFrame.from_records(loadings, index=cells_dataset.gene_names,
columns=[f'Z_{i}' for i in range(10)])
[15]:
loadings.head()
[15]:
| Z_0 | Z_1 | Z_2 | Z_3 | Z_4 | Z_5 | Z_6 | Z_7 | Z_8 | Z_9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| IGKC | 0.581352 | 0.041356 | 0.190325 | 0.515993 | -0.034975 | 0.132695 | 0.381794 | 0.088605 | 0.078768 | -0.323640 |
| IGHA1 | 0.303032 | -0.068096 | 0.248039 | 0.247651 | -0.194746 | 0.453991 | 0.160778 | 0.013388 | 0.090267 | -0.266768 |
| IGLC2 | 0.819657 | 0.207480 | 0.235532 | 0.724941 | 0.172202 | -0.010380 | 0.326365 | -0.420546 | 0.433572 | -0.171949 |
| IGLC3 | 0.818061 | 0.455800 | 0.132923 | 0.660388 | -0.087060 | -0.093394 | 0.389668 | -0.168332 | 0.151087 | -0.291709 |
| IGHM | 0.874641 | 0.312170 | 0.287022 | 0.963226 | 0.108258 | -0.034833 | 0.627738 | 0.031824 | 0.096756 | -0.368698 |
For every latent variable Z, we extract the genes with largest magnitude, and separate genes with large negative values from genes with large positive values. We print out the top 5 genes in each direction for each latent variable.
[16]:
print('Top loadings by magnitude\n---------------------')
for clmn_ in loadings:
loading_ = loadings[clmn_].sort_values()
fstr = clmn_ + ':\t'
fstr += '\t'.join([f'{i}, {loading_[i]:.2}' for i in loading_.head(5).index])
fstr += '\n\t...\n\t'
fstr += '\t'.join([f'{i}, {loading_[i]:.2}' for i in loading_.tail(5).index])
print(fstr + '\n---------------------\n')
Top loadings by magnitude
---------------------
Z_0: S100A12, -1.1 IL7R, -0.89 VCAN, -0.89 S100A8, -0.86 G0S2, -0.85
...
CD79A, 0.98 HLA-DQB1, 1.0 IGLL5, 1.1 HLA-DQA2, 1.1 HLA-DQA1, 1.3
---------------------
Z_1: ITGB1, -0.44 HBB, -0.37 KLF6, -0.29 LTB, -0.29 CORO1B, -0.26
...
FGFBP2, 0.69 TRDC, 0.72 KLRF1, 0.73 PTGDS, 0.86 GZMB, 0.91
---------------------
Z_2: C1QB, -1.0 LYPD2, -0.96 C1QA, -0.93 CDKN1C, -0.84 UBE2C, -0.55
...
DERL3, 0.35 ALOX5AP, 0.38 GZMB, 0.42 PTGDS, 0.52 IGHG2, 0.62
---------------------
Z_3: FCER1A, -0.72 CLEC10A, -0.5 S100A12, -0.49 C1QB, -0.47 PLBD1, -0.46
...
IGHG2, 0.92 IGHM, 0.96 MS4A1, 1.0 IGHD, 1.2 TCL1A, 1.2
---------------------
Z_4: KLRF1, -0.4 XBP1, -0.34 TYROBP, -0.33 MYDGF, -0.32 GNLY, -0.3
...
FCER1A, 0.45 GZMK, 0.66 PCLAF, 0.66 CD8B, 0.67 PPBP, 0.79
---------------------
Z_5: TCL1A, -0.97 C1QA, -0.94 FCGR3A, -0.87 IGHD, -0.85 C1QB, -0.77
...
PCLAF, 0.46 TYMS, 0.46 TNFRSF17, 0.51 IGHA2, 0.53 AQP3, 0.59
---------------------
Z_6: GNLY, -1.9 GZMH, -1.9 NKG7, -1.9 CCL5, -1.8 GZMA, -1.8
...
VCAN, 0.74 AIF1, 0.74 LGALS2, 0.76 KCTD12, 0.77 IGLC7, 0.79
---------------------
Z_7: GZMK, -1.4 CLEC10A, -1.2 KLRB1, -0.95 FCER1A, -0.73 CCL5, -0.69
...
PPBP, 0.45 RRM2, 0.54 HBA2, 0.59 IGHG2, 1.4 HBB, 1.5
---------------------
Z_8: LYPD2, -1.1 C1QA, -0.76 CDKN1C, -0.76 C1QB, -0.69 FCGR3A, -0.59
...
UBE2C, 0.45 ITM2C, 0.51 TCL1A, 0.53 DERL3, 0.61 GZMK, 0.61
---------------------
Z_9: CD8B, -2.2 GZMK, -1.9 TRAC, -1.7 CD3G, -1.7 CD3D, -1.6
...
CST3, 1.7 S100A12, 1.7 S100A8, 1.9 S100A9, 1.9 LYZ, 1.9
---------------------
It is important to keep in mind that unlike traditional PCA, these latent variables are not ordered. Z_0 does not necessarily explain more variance than Z_1.
These top genes can be interpreted as following most of the structural variation in the data.
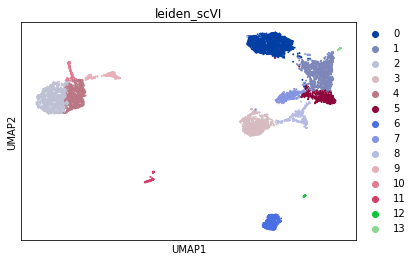
The LDVAE model further supports the same scVI functionality as the VAE model, so all posterior methods work the same. Here we show how to use scanpy to visualize the latent space.
[17]:
adata.obsm["X_scVI"] = Z_hat
sc.pp.neighbors(adata, use_rep="X_scVI", n_neighbors=20)
sc.tl.umap(adata, min_dist=0.1)
sc.tl.leiden(adata, key_added="leiden_scVI", resolution=0.8)
[18]:
sc.pl.umap(adata, color=["leiden_scVI"], show=show_plot)
[19]:
zs = [f'Z_{i}' for i in range(vae.n_latent)]
sc.pl.umap(adata, color=zs, show=show_plot, ncols=3)
