Joint analysis of paired and unpaired multiomic data with MultiVI#
MultiVI is used for the joint analysis of scRNA and scATAC-seq datasets that were jointly profiled (multiomic / paired) and single-modality datasets (only scRNA or only scATAC). MultiVI uses the paired data as an anchor to align and merge the latent spaces learned from each individual modality.
This tutorial walks through how to read multiomic data, create a joint object with paired and unpaired data, set-up and train a MultiVI model, visualize the resulting latent space, and run differential analyses.
Note
Running the following cell will install tutorial dependencies on Google Colab only. It will have no effect on environments other than Google Colab.
!pip install --quiet scvi-colab
from scvi_colab import install
install()
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager, possibly rendering your system unusable. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv. Use the --root-user-action option if you know what you are doing and want to suppress this warning.
[notice] A new release of pip is available: 25.0.1 -> 25.1.1
[notice] To update, run: pip install --upgrade pip
import os
import tempfile
import muon
import numpy as np
import requests
import scanpy as sc
import scvi
import seaborn as sns
import torch
scvi.settings.seed = 0
print("Last run with scvi-tools version:", scvi.__version__)
Last run with scvi-tools version: 1.3.2
Note
You can modify save_dir below to change where the data files for this tutorial are saved.
sc.set_figure_params(figsize=(6, 6), frameon=False)
sns.set_theme()
torch.set_float32_matmul_precision("high")
save_dir = tempfile.TemporaryDirectory()
%config InlineBackend.print_figure_kwargs={"facecolor": "w"}
%config InlineBackend.figure_format="retina"
Data acquisition#
First we download a sample multiome dataset from 10X, which we have preprocessed in a way similar to what is demonstrated in the scvi-tools preprocessing tutorial (Note: the exact dataset was not used in the preprocessing tutorial). We’ll use this throughout this tutorial. Importantly, MultiVI assumes that there are shared features between the datasets. This is trivial for gene expression datasets, which generally use the same set of genes as features. For ATAC-seq peaks, this is less trivial, and often requires preprocessing steps with other tools to get all datasets to use a shared set of peaks. That can be achieved with tools like SnapATAC, ArchR, and CellRanger in the case of 10X data.
Important
MultiVI requires the datasets to use shared features. scATAC-seq datasets need to be processed to use a shared set of peaks.
Note
The original 10X dataset has been modified to remove some modality specific data such that 1/3 of the cells contain just gene expression data, 1/3 contain both gene expression and peaks data, and the remaining 1/3 of cells contain just peaks. The modification was done in order to demonstrate MultiVI’s ability to mix multimodal and single-modal data. The dataset has 12012 cells total
Below we download the already preprocessed dataset.
# download preprocessed dataset
mdata_path = os.path.join(save_dir.name, "pbmc_10k_preprocessed.h5mu")
# Figshare direct download URL
url = "https://figshare.com/ndownloader/files/54794234"
# Download only if file doesn't already exist
if not os.path.exists(mdata_path):
print(f"Downloading MuData file to {mdata_path}...")
r = requests.get(url)
with open(mdata_path, "wb") as f:
f.write(r.content)
# Load the MuData object
mdata = muon.read_h5mu(mdata_path)
Downloading MuData file to /tmp/tmp37yox4v4/pbmc_10k_preprocessed.h5mu...
Important
MultiVI requires the features to be ordered so that genes appear before genomic regions. This must be enforced by the user.
Setup and Training MultiVI#
We can now set up and train the MultiVI model!
First, we need to setup the Anndata object using the setup_anndata function. At this point we specify any batch annotation that the model would account for.
Importantly, the main batch annotation, specific by batch_key, should correspond to the modality of the cells.
Other batch annotations (e.g if there are multiple ATAC batches) should be provided using the categorical_covariate_keys.
The actual values of categorical covariates (include batch_key) are not important, as long as they are different for different samples.
I.e it is not important to call the expression-only samples “expression”, as long as they are called something different than the multi-modal and accessibility-only samples.
Important
MultiVI requires the main batch annotation to correspond to the modality of the samples. Other batch annotation, such as in the case of multiple RNA-only batches, can be specified using categorical_covariate_keys.
mdata
MuData object with n_obs × n_vars = 12012 × 8000
var: 'gene_ids', 'feature_types', 'highly_variable', 'highly_variable_rank', 'means', 'variances', 'variances_norm'
2 modalities
rna_subset: 12012 x 4000
var: 'gene_ids', 'feature_types', 'highly_variable', 'highly_variable_rank', 'means', 'variances', 'variances_norm'
uns: 'hvg'
atac_subset: 12012 x 4000
var: 'gene_ids', 'feature_types', 'highly_variable', 'highly_variable_rank', 'means', 'variances', 'variances_norm'
uns: 'hvg'scvi.model.MULTIVI.setup_mudata(
mdata,
modalities={
"rna_layer": "rna_subset",
"atac_layer": "atac_subset",
},
)
When creating the object, we need to specify how many of the features are genes, and how many are genomic regions. This is so MultiVI can determine the exact architecture for each modality.
model = scvi.model.MULTIVI(
mdata,
n_genes=len(mdata.mod["rna_subset"].var),
n_regions=len(mdata.mod["atac_subset"].var),
)
model.view_anndata_setup()
Anndata setup with scvi-tools version 1.3.2.
Setup via `MULTIVI.setup_anndata` with arguments:
{ │ 'rna_layer': None, │ 'atac_layer': None, │ 'protein_layer': None, │ 'batch_key': None, │ 'size_factor_key': None, │ 'categorical_covariate_keys': None, │ 'continuous_covariate_keys': None, │ 'idx_layer': None, │ 'modalities': {'rna_layer': 'rna_subset', 'atac_layer': 'atac_subset'} }
Summary Statistics ┏━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━┓ ┃ Summary Stat Key ┃ Value ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━┩ │ n_atac │ 4000 │ │ n_batch │ 1 │ │ n_cells │ 12012 │ │ n_extra_categorical_covs │ 0 │ │ n_extra_continuous_covs │ 0 │ │ n_labels │ 1 │ │ n_size_factor │ 0 │ │ n_vars │ 4000 │ └──────────────────────────┴───────┘
Data Registry ┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Registry Key ┃ scvi-tools Location ┃ ┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ X │ adata.mod['rna_subset'].X │ │ atac │ adata.mod['atac_subset'].X │ │ batch │ adata.obs['_scvi_batch'] │ │ ind_x │ adata.obs['_indices'] │ │ labels │ adata.obs['_scvi_labels'] │ └──────────────┴────────────────────────────┘
batch State Registry ┏━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┓ ┃ Source Location ┃ Categories ┃ scvi-tools Encoding ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━┩ │ adata.obs['_scvi_batch'] │ 0 │ 0 │ └──────────────────────────┴────────────┴─────────────────────┘
labels State Registry ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┓ ┃ Source Location ┃ Categories ┃ scvi-tools Encoding ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━┩ │ adata.obs['_scvi_labels'] │ 0 │ 0 │ └───────────────────────────┴────────────┴─────────────────────┘
# For our sparse matrices, we want CSR rather than CSC as training will be faster
# We convert here since our downloaded dataset uses CSC (might not be the case for other datasets)
mdata.mod["rna_subset"].X = mdata.mod["rna_subset"].X.tocsr()
mdata.mod["atac_subset"].X = mdata.mod["atac_subset"].X.tocsr()
mdata.update()
model.train()
Monitored metric reconstruction_loss_validation did not improve in the last 50 records. Best score: 928.342. Signaling Trainer to stop.
Save and Load MultiVI models#
Saving and loading models is similar to all other scvi-tools models, and is very straight forward:
model_dir = os.path.join(save_dir.name, "multivi_pbmc10k")
model.save(model_dir, overwrite=True)
model = scvi.model.MULTIVI.load(model_dir, adata=mdata)
INFO File /tmp/tmp37yox4v4/multivi_pbmc10k/model.pt already downloaded
mdata = model.adata
model = scvi.model.MULTIVI.load(model_dir, adata=mdata)
INFO File /tmp/tmp37yox4v4/multivi_pbmc10k/model.pt already downloaded
mdata
MuData object with n_obs × n_vars = 12012 × 8000
obs: '_indices', '_scvi_batch', '_scvi_labels'
var: 'gene_ids', 'feature_types', 'highly_variable', 'highly_variable_rank', 'means', 'variances', 'variances_norm'
uns: '_scvi_uuid', '_scvi_manager_uuid'
2 modalities
rna_subset: 12012 x 4000
var: 'gene_ids', 'feature_types', 'highly_variable', 'highly_variable_rank', 'means', 'variances', 'variances_norm'
uns: 'hvg'
atac_subset: 12012 x 4000
var: 'gene_ids', 'feature_types', 'highly_variable', 'highly_variable_rank', 'means', 'variances', 'variances_norm'
uns: 'hvg'Extracting and visualizing the latent space#
We can now use the get_latent_representation to get the latent space from the trained model, and visualize it using scanpy functions:
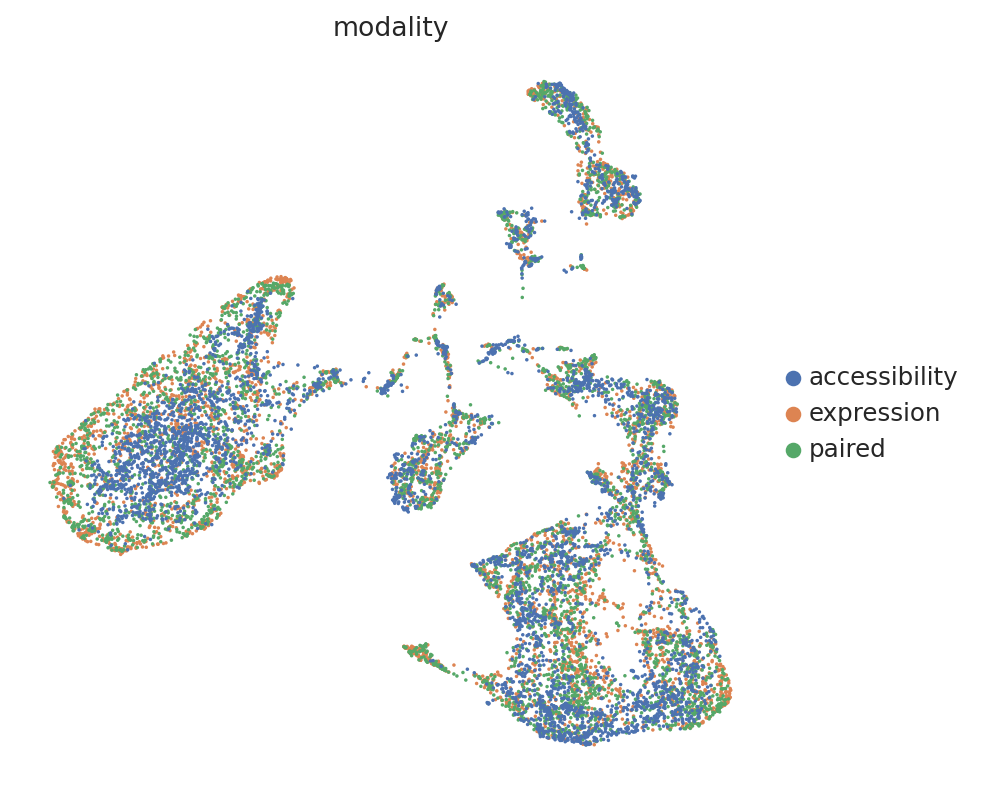
# Below we an cell annotations for modality, so we can color the UMAP
MULTIVI_LATENT_KEY = "X_multivi"
mdata.obsm[MULTIVI_LATENT_KEY] = model.get_latent_representation()
sc.pp.neighbors(mdata, use_rep=MULTIVI_LATENT_KEY)
sc.tl.umap(mdata, min_dist=0.2)
n = mdata.n_obs // 3
# initialize the column first
mdata.obs["modality"] = ""
# set modality of first third to rna
mdata.obs.iloc[:n, mdata.obs.columns.get_loc("modality")] = "expression"
# set modality of second third to both
mdata.obs.iloc[n : 2 * n, mdata.obs.columns.get_loc("modality")] = "paired"
# set modality of last third to atac
mdata.obs.iloc[2 * n :, mdata.obs.columns.get_loc("modality")] = "accessibility"
sc.pl.umap(mdata, color="modality")
Impute missing modalities#
In a well-mixed space, MultiVI can seamlessly impute the missing modalities for single-modality cells.
First, imputing expression and accessibility is done with get_normalized_expression and get_accessibility_estimates, respectively.
We’ll demonstrate this by imputing gene expression for all cells in the dataset (including those that are ATAC-only cells):
imputed_expression = model.get_normalized_expression()
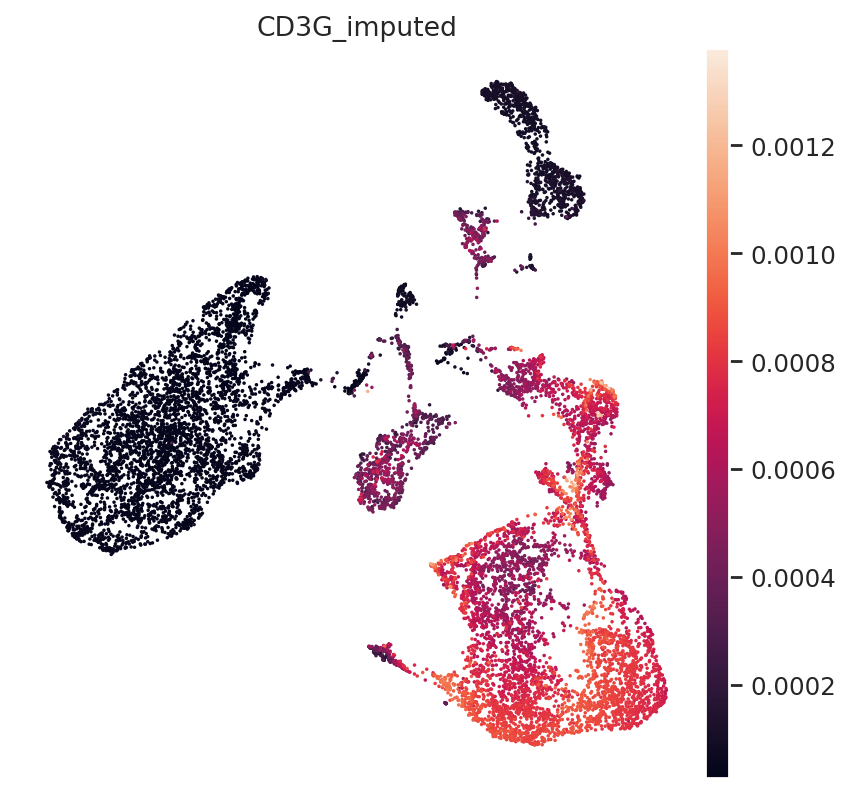
We can demonstrate this on some known marker genes:
First, T-cell marker CD3.
mdata.mod["rna_subset"].var.index
Index(['PLEKHN1', 'HES4', 'ISG15', 'TNFRSF18', 'TNFRSF4', 'TAS1R3', 'ANKRD65',
'PRDM16', 'SMIM1', 'AJAP1',
...
'SRPK3', 'SSR4', 'RPL10', 'CLIC2', 'LINC00278', 'PRKY', 'UTY', 'TTTY14',
'EIF1AY', 'AC233755.2'],
dtype='object', length=4000)
np.where(mdata.mod["rna_subset"].var.index == "CD3G")
(array([2489]),)
gene_idx = np.where(mdata.mod["rna_subset"].var.index == "CD3G")[0]
mdata.obs["CD3G_imputed"] = imputed_expression.iloc[:, gene_idx]
sc.pl.umap(mdata, color="CD3G_imputed")
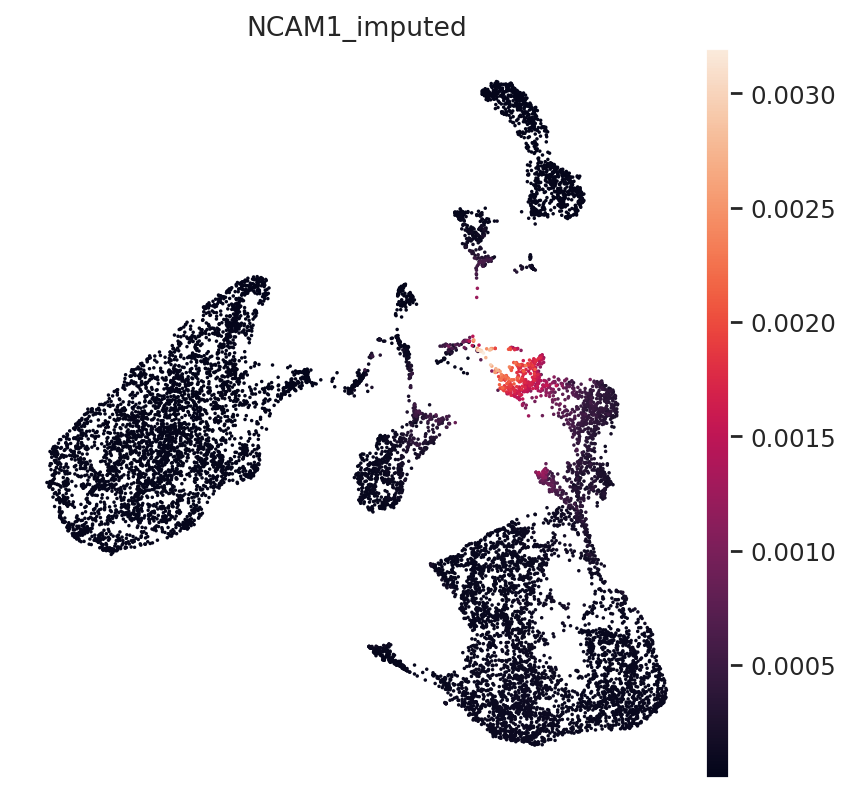
Next, NK-Cell marker gene NCAM1 (CD56):
gene_idx = np.where(mdata.var.index == "NCAM1")[0]
mdata.obs["NCAM1_imputed"] = imputed_expression.iloc[:, gene_idx]
sc.pl.umap(mdata, color="NCAM1_imputed")
Finally, B-Cell Marker MS4A1:
gene_idx = np.where(mdata.var.index == "MS4A1")[0]
mdata.obs["MS4A1_imputed"] = imputed_expression.iloc[:, gene_idx]
sc.pl.umap(mdata, color="MS4A1_imputed")
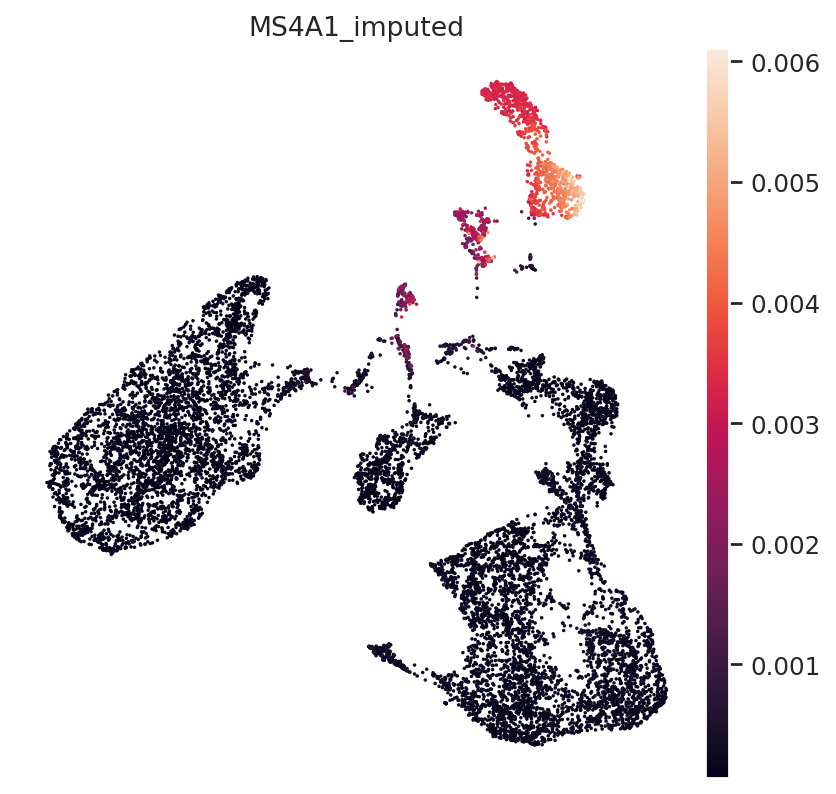
All three marker genes clearly identify their respective populations. Importantly, the imputed gene expression profiles are stable and consistent within that population, even though many of those cells only measured the ATAC profile of those cells.