Multi-resolution deconvolution of spatial transcriptomics#
In this tutorial, we through the steps of applying DestVI for deconvolution of 10x Visium spatial transcriptomics profiles using an accompanying single-cell RNA sequencing data.
Background:
Spatial transcriptomics technologies are currently limited, because their resolution is limited to niches (spots) of sizes well beyond that of a single cell. Although several pipelines proposed joint analysis with single-cell RNA-sequencing (scRNA-seq) to alleviate this problem they are limited to a discrete view of cell type proportion inside every spot. This limitation becomes critical in the common case where, even within a cell type, there is a continuum of cell states. We present Deconvolution of Spatial Transcriptomics profiles using Variational Inference (DestVI), a probabilistic method for multi-resolution analysis for spatial transcriptomics that explicitly models continuous variation within cell types.
Plan for this tutorial:
Loading the data
Training the single-cell model (scLVM) to learn a basis of gene expression on the scRNA-seq data
Training the spatial model (stLVM) to perform the deconvolution
Visualize the learned cell type proportions
Run our automated pipeline
Dig into the intra cell type information
Run cell-type specific differential expression
Note
Running the following cell will install tutorial dependencies on Google Colab only. It will have no effect on environments other than Google Colab.
!pip install --quiet scvi-colab
from scvi_colab import install
install()
#!pip install --quiet git+https://github.com/yoseflab/destvi_utils.git@main
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager, possibly rendering your system unusable. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv. Use the --root-user-action option if you know what you are doing and want to suppress this warning.
[notice] A new release of pip is available: 25.0.1 -> 25.1.1
[notice] To update, run: pip install --upgrade pip
import os
import tempfile
# import destvi_utils
import matplotlib.pyplot as plt
import numpy as np
import scanpy as sc
import scvi
import seaborn as sns
import torch
from scvi.model import CondSCVI, DestVI
scvi.settings.seed = 0
print("Last run with scvi-tools version:", scvi.__version__)
Last run with scvi-tools version: 1.3.1.post1
Note
You can modify save_dir below to change where the data files for this tutorial are saved.
sc.set_figure_params(figsize=(6, 6), frameon=False)
sns.set_theme()
torch.set_float32_matmul_precision("high")
save_dir = tempfile.TemporaryDirectory()
%config InlineBackend.print_figure_kwargs={"facecolor": "w"}
%config InlineBackend.figure_format="retina"
Data loading & processing#
First, let’s load the single-cell data. We profiled immune cells from murine lymph nodes with 10x Chromium, as a control / case study to study the immune response to exposure to a mycobacteria (refer to our paper for more info). We provide the preprocessed data from our reproducibility repository: it contains the raw counts (DestVI always takes raw counts as input).
Let’s download our data from a comparative study of murine lymph nodes, comparing wild-type with a stimulation after injection of a mycobacteria. We have at disposal a 10x Visium dataset as well as a matching scRNA-seq dataset from the same tissue.
Note
Below we download the already preprocessed datasets. To see the exact preprocssing procedure on these datasets, please see the spatial section of the preprocessing tutorial:
st_adata_path = os.path.join(save_dir.name, "st_lymph_node_preprocessed.h5ad")
st_adata = sc.read(
st_adata_path,
backup_url="https://figshare.com/ndownloader/files/52947032",
)
st_adata
AnnData object with n_obs × n_vars = 1092 × 1888
obs: 'in_tissue', 'array_row', 'array_col', 'batch', 'LN', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'pct_counts_in_top_50_genes', 'pct_counts_in_top_100_genes', 'pct_counts_in_top_200_genes', 'pct_counts_in_top_500_genes', 'total_counts_mt', 'log1p_total_counts_mt', 'pct_counts_mt', 'n_counts', 'leiden', 'lymph_node'
var: 'gene_ids', 'feature_types', 'genome', 'mt', 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts', 'n_cells'
uns: 'LN_colors', 'log1p'
obsm: 'X_pca', 'X_umap', 'location', 'modules', 'spatial'
layers: 'counts'
sc_adata_path = os.path.join(save_dir.name, "sc_lymph_node_preprocessed.h5ad")
sc_adata = sc.read(
sc_adata_path,
backup_url="https://figshare.com/ndownloader/files/52947086",
)
sc_adata
AnnData object with n_obs × n_vars = 14989 × 1888
obs: 'n_genes', 'cell_types', 'batch', 'n_genes_by_counts', 'total_counts', 'total_counts_mt', 'pct_counts_mt', 'pred_cell_types', 'doublet_scores', 'doublet_predictions', 'MS', 'louvain_r0.5', 'louvain_r0.7', 'louvain_r1.0', 'leiden_r0.5', 'leiden_r0.7', 'leiden_r1.0', 'DC_A', 'DC_B', 'mono_1', 'mono_2', 'louvain_sub_0.1', 'louvain_sub_0.2', 'louvain_sub_0.3', 'louvain_sub', 'louvain_sub_1', 'louvain_sub_2', 'louvain_sub_3', 'SCANVI_pred_cell_types', 'SCVI_pred_cell_types', 'broad_cell_types'
var: 'gene_ids-0', 'genome-0', 'n_cells', 'mt', 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'highly_variable', 'n_counts', 'highly_variable_rank', 'means', 'variances', 'variances_norm'
uns: 'batch_colors', 'hvg', 'leiden', 'leiden_r1.0_colors', 'log1p', 'louvain', 'louvain_r0.5_colors', 'louvain_r0.7_colors', 'louvain_r1.0_colors', 'louvain_sub_0.2_colors', 'louvain_sub_0.3_colors', 'louvain_sub_1_colors', 'neighbors', 'pred_cell_types_colors', 'umap'
obsm: 'X_scVI', 'X_umap'
layers: 'counts'
obsp: 'connectivities', 'distances'
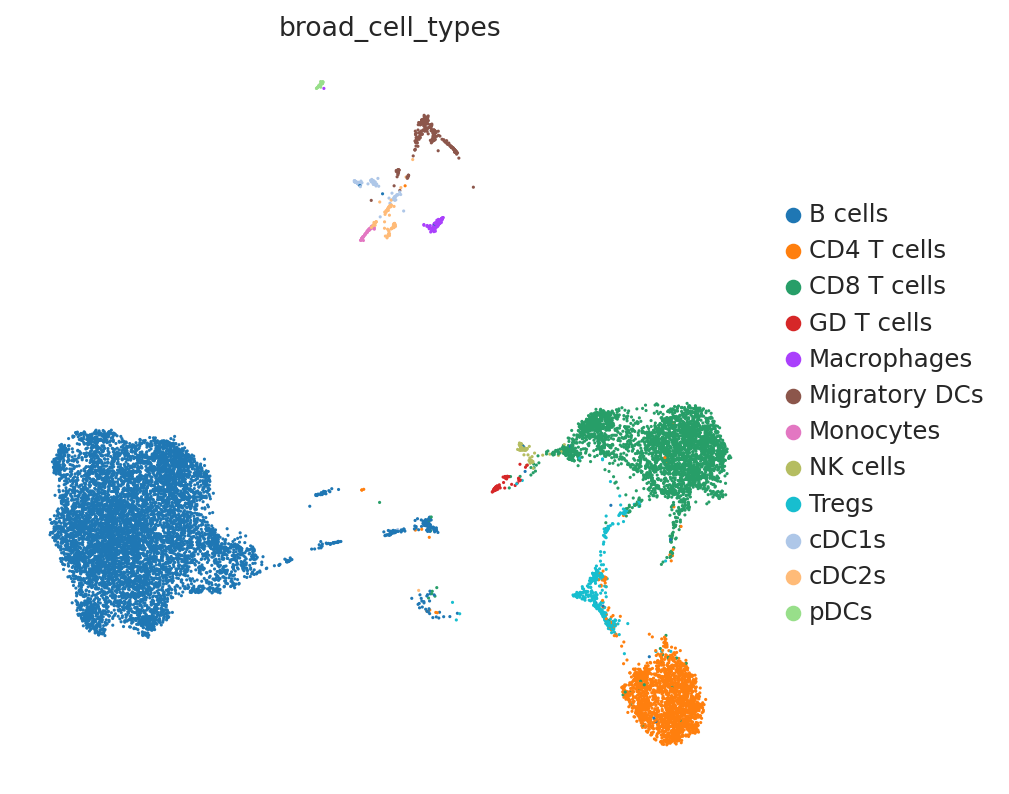
We clustered the single-cell data by major immune cell types. DestVI can resolve beyond discrete clusters, but need to work with an existing level of clustering. A rule of thumb to keep in mind while clsutering is that DestVI assumes only a single state from each cell type exists in each spot. For example, resting and inflammed monocytes cannot co-exist in one unique spot according to our assumption. Users may cluster their data so that this modeling assumption is as accurate as possible.
sc.pl.umap(sc_adata, color="broad_cell_types")
G = len(sc_adata.var_names)
sc.pl.embedding(st_adata, basis="spatial", color="lymph_node", s=80)

Fit the scLVM#
In order to learn cell state specific gene expression patterns, we will fit the single-cell Latent Variable Model (scLVM) to single-cell RNA sequencing data from the same tissue.
CondSCVI.setup_anndata(sc_adata, layer="counts", labels_key="broad_cell_types")
As a first step, we embed our data using a cell type conditional VAE. We pass the layer containing the raw counts and the labels key. We train this model without reweighting the loss by the cell type abundance. Training will take around 5 minutes in a Colab GPU session.
sc_model = CondSCVI(sc_adata, weight_obs=False)
sc_model.view_anndata_setup()
Anndata setup with scvi-tools version 1.3.1.post1.
Setup via `CondSCVI.setup_anndata` with arguments:
{'labels_key': 'broad_cell_types', 'layer': 'counts', 'batch_key': None}
Summary Statistics ┏━━━━━━━━━━━━━━━━━━┳━━━━━━━┓ ┃ Summary Stat Key ┃ Value ┃ ┡━━━━━━━━━━━━━━━━━━╇━━━━━━━┩ │ n_batch │ 1 │ │ n_cells │ 14989 │ │ n_labels │ 12 │ │ n_vars │ 1888 │ └──────────────────┴───────┘
Data Registry ┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Registry Key ┃ scvi-tools Location ┃ ┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ X │ adata.layers['counts'] │ │ batch │ adata.obs['_scvi_batch'] │ │ labels │ adata.obs['_scvi_labels'] │ └──────────────┴───────────────────────────┘
labels State Registry ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┓ ┃ Source Location ┃ Categories ┃ scvi-tools Encoding ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━┩ │ adata.obs['broad_cell_types'] │ B cells │ 0 │ │ │ CD4 T cells │ 1 │ │ │ CD8 T cells │ 2 │ │ │ GD T cells │ 3 │ │ │ Macrophages │ 4 │ │ │ Migratory DCs │ 5 │ │ │ Monocytes │ 6 │ │ │ NK cells │ 7 │ │ │ Tregs │ 8 │ │ │ cDC1s │ 9 │ │ │ cDC2s │ 10 │ │ │ pDCs │ 11 │ └───────────────────────────────┴───────────────┴─────────────────────┘
batch State Registry ┏━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┓ ┃ Source Location ┃ Categories ┃ scvi-tools Encoding ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━┩ │ adata.obs['_scvi_batch'] │ 0 │ 0 │ └──────────────────────────┴────────────┴─────────────────────┘
sc_model.train()
sc_model.history["elbo_train"].iloc[5:].plot()
plt.show()

Note that model converges quickly. Over experimentation with the model drastically reducing the number of epochs leads to decreased performance and performance deteriorates as max_epochs<200.
Deconvolution with stLVM#
As a second step, we train our deconvolution model: spatial transcriptomics Latent Variable Model (stLVM).
We setup the DestVI model using the counts layer in st_adata that contains the raw counts. We then pass the trained CondSCVI model and generate a new model based on st_adata and sc_model using DestVI.from_rna_model.
The decoder network architecture will be generated from sc_model. Two neural networks are initiated for cell type proportions and gamma value amortization. Training will take around 5 minutes in a Colab GPU session.
Potential adaptations of DestVI.from_rna_model are:
increasing
vamp_prior_pleads to less gradual changes in gamma valuesmore discretized values. Increasing
l1_sparsitywill lead to sparser results for cell type proportions.Although we recommend using similar sequencing technology for both assays, consider changing
beta_weighting_priorotherwise.
Technical Note: During inference, we adopt a variational mixture of posterior as a prior to enforce gamma values in stLVM match scLVM (see details in original publication). This empirical prior is based on cell type specific subclustering (using k-means to find vamp_prior_p clusters) of the posterior distribution in latent space for every cell.
DestVI.setup_anndata(st_adata, layer="counts")
st_model = DestVI.from_rna_model(st_adata, sc_model)
st_model.view_anndata_setup()
Anndata setup with scvi-tools version 1.3.1.post1.
Setup via `DestVI.setup_anndata` with arguments:
{'layer': 'counts'}
Summary Statistics ┏━━━━━━━━━━━━━━━━━━┳━━━━━━━┓ ┃ Summary Stat Key ┃ Value ┃ ┡━━━━━━━━━━━━━━━━━━╇━━━━━━━┩ │ n_cells │ 1092 │ │ n_vars │ 1888 │ └──────────────────┴───────┘
Data Registry ┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Registry Key ┃ scvi-tools Location ┃ ┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━┩ │ X │ adata.layers['counts'] │ │ ind_x │ adata.obs['_indices'] │ └──────────────┴────────────────────────┘
st_model.train(max_epochs=2500)
Note that model converges quickly. Over experimentation with the model drastically reducing the number of epochs leads to decreased performance and we advocate against max_epochs<1000.
st_model.history["elbo_train"].iloc[10:].plot()
plt.show()
The output of DestVI has two resolution. At the broader resolution, DestVI returns the cell type proportion in every spot. At the more granular resolution, DestVI can impute cell type specific gene expression in every spot.
Cell type proportions#
We extract the computed cell type proportions and display them in spatial embedding. These values are directly calculated by normalized the spot-level parameters from the stLVM model.
st_adata.obsm["proportions"] = st_model.get_proportions()
st_adata.obsm["proportions"].head(5)
| B cells | CD4 T cells | CD8 T cells | GD T cells | Macrophages | Migratory DCs | Monocytes | NK cells | Tregs | cDC1s | cDC2s | pDCs | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AAACCGGGTAGGTACC-1-0 | 0.692519 | 0.040952 | 0.006659 | 0.005054 | 0.024756 | 0.063314 | 0.016873 | 0.006543 | 0.055208 | 0.015495 | 0.062650 | 0.009977 |
| AAACCTCATGAAGTTG-1-0 | 0.631342 | 0.060640 | 0.017318 | 0.006754 | 0.018324 | 0.063491 | 0.016200 | 0.003559 | 0.064428 | 0.029151 | 0.083311 | 0.005482 |
| AAAGACTGGGCGCTTT-1-0 | 0.585061 | 0.089210 | 0.025808 | 0.005747 | 0.011452 | 0.057290 | 0.006532 | 0.010079 | 0.055005 | 0.041992 | 0.109121 | 0.002704 |
| AAAGGGCAGCTTGAAT-1-0 | 0.070126 | 0.229078 | 0.236169 | 0.012128 | 0.011742 | 0.083426 | 0.024458 | 0.055758 | 0.125949 | 0.060392 | 0.087609 | 0.003164 |
| AAAGTCGACCCTCAGT-1-0 | 0.823370 | 0.032167 | 0.000184 | 0.004942 | 0.014909 | 0.009829 | 0.005133 | 0.003063 | 0.013690 | 0.021595 | 0.068340 | 0.002778 |
ct_list = ["B cells", "CD8 T cells", "Monocytes"]
for ct in ct_list:
data = st_adata.obsm["proportions"][ct].values
st_adata.obs[ct] = np.clip(data, 0, np.quantile(data, 0.99))
sc.pl.embedding(st_adata, basis="spatial", color=ct_list, cmap="Reds", s=80)

Because the inference of cell type specific gene expression is prone to error when the cell type is not present in a spot, and because the cell type proportion values estimated by stLVM are not sparse, we provide an automated way of thresholding them. For follow-up analysis we recommend checking these threshold values and adjust them for each cell type.
This part of the software is not directly available in scvi-tools, but instead in the util package destvi_utils (installable from GitHub; refer to the top of this tutorial).
Important
The destvi_utils package is not compatable with the current version of scvi-tools. This will be fixed in an upcoming release. Until then, the dest_utils dependent code will not run.
ct_thresholds = destvi_utils.automatic_proportion_threshold( st_adata, ct_list=ct_list, kind_threshold=”secondary” )
In terms of cell type location, we observe a strong compartimentalization of the cell types in the lymph node (B cells / T cells), as expected. We also observe a differential localization of the monocytes (refer to the paper for further details).
Intra cell type information#
At the heart of DestVI is a multitude of latent variables (5 per cell type per spots). We refer to them as “gamma”, and we may manually examine them for downstream analysis
# more globally, the values of the gamma are all summarized in this dictionary of data frames
for ct, g in st_model.get_gamma().items():
st_adata.obsm[f"{ct}_gamma"] = g
st_adata.obsm["B cells_gamma"].head(5)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| AAACCGGGTAGGTACC-1-0 | -0.147902 | 0.459822 | -0.688280 | 0.209828 | -0.033888 |
| AAACCTCATGAAGTTG-1-0 | -1.421715 | -0.756322 | -1.360905 | -0.133848 | 0.002506 |
| AAAGACTGGGCGCTTT-1-0 | -2.238851 | -0.439353 | -1.114501 | 0.159616 | -0.582106 |
| AAAGGGCAGCTTGAAT-1-0 | -0.431411 | -0.424665 | 0.145604 | 0.310615 | -0.492182 |
| AAAGTCGACCCTCAGT-1-0 | 0.145129 | 0.336156 | -0.409777 | -0.382592 | 0.682123 |
Because those values may be hard to examine manually for end-users, we presented in the manuscript several methods for prioritizing the study of different cell types (based on spatially-weighted PCA and Hotspot). Below we provide the result of our automated pipeline with the spatially-weighted PCA.
More precisely, for de novo detection of spatial patterns, we study the gamma space and use a spatially-informed PCA to find the spatial axis of variation in this gamma space. We use EnrichR to functionally annotate these genes. In particular, we recover enrichment of IFN genes across monocytes as well as B cells
The function explore_gamma_space operates as follow, for each cell type individually:
Select all the spots with proportions beyond the magnitude threshold,
Calculate the spot-specific cell-type-specific embeddings gamma,
Calculate the first two principal vectors of those gamma values, weighted by the spatial coordinates,
Project all the embeddings (considered spots, and single-cell profiles) onto this 2D space,
Map each spot (or cell) to a specific color via its 2d coordinate, using the
cmap2dpackagePlot (A) the color of every spot in spatial coordinates (B) the color of every spot in sPC space (C) the color of every single cell in sPC space
Calculate genes enriched in each direction and group into pathways with
EnrichR
destvi_utils.explore_gamma_space( st_model, sc_model, ct_list=ct_list, ct_thresholds=ct_thresholds)
We anticipate this to be a valuable ressource for formulating scientific hypotheses from ST data.
Example with B cells; and differential expression#
First, we display the genes identified via the pipeline as well as Hotspot (see manuscript), using the B-cell-specific gene expression values imputed by DestVI.
plt.figure(figsize=(8, 8))
ct_name = "B cells"
gene_name = ["Ifit3", "Ifit3b", "Ifit1", "Isg15", "Oas3", "Usp18", "Isg20"]
# we must filter spots with low abundance (consult the paper for an automatic procedure)
indices = np.where(st_adata.obsm["proportions"][ct_name].values > 0.2)[0]
# impute genes and combine them
specific_expression = np.sum(st_model.get_scale_for_ct(ct_name, indices=indices)[gene_name], 1)
specific_expression = np.log(1 + 1e4 * specific_expression)
# plot (i) background (ii) g
plt.scatter(st_adata.obsm["location"][:, 0], st_adata.obsm["location"][:, 1], alpha=0.05)
plt.scatter(
st_adata.obsm["location"][indices][:, 0],
st_adata.obsm["location"][indices][:, 1],
c=specific_expression,
s=10,
cmap="Reds",
)
plt.colorbar()
plt.title(f"Imputation of {gene_name} in {ct_name}")
plt.show()

Second, we apply a Kolmogorov-Smirnov test on the generated counts to study the differential expression of B cells in the exposed lymph nodes, between the interfollicular area (IFA) and the rest. We display the identified IFN genes in a Volcano plot and see significant upregulation in the IFA area of exposed lymph nodes.
ct = “B cells” imputation = st_model.get_scale_for_ct(ct) color = np.log(1 + 1e5 * imputation[“Ifit3”].values) threshold = 4
mask = np.logical_and( np.logical_or(st_adata.obs[“LN”] == “TC”, st_adata.obs[“LN”] == “BD”), color > threshold, ).values
mask2 = np.logical_and( np.logical_or(st_adata.obs[“LN”] == “TC”, st_adata.obs[“LN”] == “BD”), color < threshold, ).values
_ = destvi_utils.de_genes( st_model, mask=mask, mask2=mask2, threshold=ct_thresholds[ct], ct=ct, key=”IFN_rich” )
display(st_adata.uns[“IFN_rich”][“de_results”].head(10))
destvi_utils.plot_de_genes( st_adata, interesting_genes=[“Ifit3”, “Ifit3b”, “Ifit1”, “Isg15”, “Oas3”, “Usp18”, “Isg20”], key=”IFN_rich”, )