Using scvi-hub to download pretrained scvi-tools models#
In this tutorial, we will learn about Hugging Face and the scvi-hub, and how you can use it to download pretrained scvi-tools models.
Note
Running the following cell will install tutorial dependencies on Google Colab only. It will have no effect on environments other than Google Colab.
!pip install --quiet scvi-colab
from scvi_colab import install
install()
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager, possibly rendering your system unusable. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv. Use the --root-user-action option if you know what you are doing and want to suppress this warning.
[notice] A new release of pip is available: 25.0.1 -> 26.1.2
[notice] To update, run: pip install --upgrade pip
import tempfile
import scanpy as sc
import scvi
import seaborn as sns
import torch
scvi.settings.seed = 0
print("Last run with scvi-tools version:", scvi.__version__)
Last run with scvi-tools version: 1.5.0
Note
You can modify save_dir below to change where the data files for this tutorial are saved.
sc.set_figure_params(figsize=(4, 4), frameon=False)
sns.set_theme()
torch.set_float32_matmul_precision("high")
save_dir = tempfile.TemporaryDirectory()
%config InlineBackend.print_figure_kwargs={"facecolor" : "w"}
%config InlineBackend.figure_format="retina"
Overview#
TL;DR: Hugging Face is a Cloud-based platform that’s ideal for storage and sharing of pre-trained ML models. We provide an interface to it in scvi-tools and store pre-trained scvi-tools models on the Hugging Face Model Hub. Read on for more details or jump here for practical examples.
What is Hugging Face 🤗?#
Hugging Face (HF for short) is a suite of tools for building ML-based applications.
The Hugging Face Hub is a platform for sharing and using pretrained models, as well as other entities such as datasets and demo apps (called Spaces). The Model Hub — the HF Hub for pretained models — includes models trained on a variety of tasks including but not limited to NLP, computer vision, audio, and many other domains. You can find more information about the HF Hub here and about the HF Model Hub here.
Here are a few interesting characteristics of the HF Model Hub that make it ideal for model-sharing:
Git-based. The hub is built on top of Github. This means that you can use all the features of Github to manage your models. For example, you can use Github’s pull requests to review changes before committing them. This also means that you can use Github’s version control to track changes to your models.
Community Tab. Models feature a Community Tab that allows users to ask questions and report issues. This is a great way to get feedback on your models and to help others who are using your models.
Model Cards. All models have a uniform UI that makes it easy to find information about the model, without being overly prescriptive. This is realized in the form of a README.md file that serves as the Model Card. The Model Card is a great way to document your model and to provide information about how to use it. You can find more information about the Model Card here.
Discoverability. You can tag models with a variety of tags to make it easier for users to find your model. For example, you can tag your model with the task it was trained on, the language it uses, the framework it was trained with, and more, including custom tags. These can then be used by users when searching for your model. You can also use the search bar to search for models by name.
What is scvi-hub?#
scvi-hub, accessible via import scvi.hub, allows programmatic access to Hugging Face for uploading (pushing) and downloading (pulling) pretrained model. Under the hood, scvi-hub uses the huggingface_hub Python API to interact with the HF Model Hub.
A few ways in which scvi-hub is useful:
Enables HF upload/download operations directly from scvi-tools, so you don’t have to learn how to use the
huggingface_hubAPILazily loads data and models into memory by deferring loading — and in some cases large data downloads — unless and until you need them
Provides helpers for creating Model Cards and Hub Models given only the directory where your pretrained model is stored. This way we’ll pull out all the interesting info from the model/data objects and populate the Model Card with it so you don’t have to.
Provides a common template for the Model Card that you’re encouraged — but not required — to use. This makes most scvi-tools models look consistent on the HF Model Hub. However this is a convenience and not a requirement. You can always create your own Model Card. scvi-tools does not take any dependency on the contents of the Model Card (including the tags). More on this later.
The second thing the term scvi-hub designates is the collection of pretrained scvi-tools models that are hosted on the HF Model Hub. Currently you can see all such models by clicking here. Soon, scvi-tools will be a first-class citizen library on the HF Model Hub, which means that you will be able to find all scvi-tools models by clicking on ths scvi-tools library button as shown below.
Anatomy of a pretrained scvi-tools model on the HF model hub#
Here is an example of a scvi-tools model pretrained on synthetic data. Below we highlight its different components.
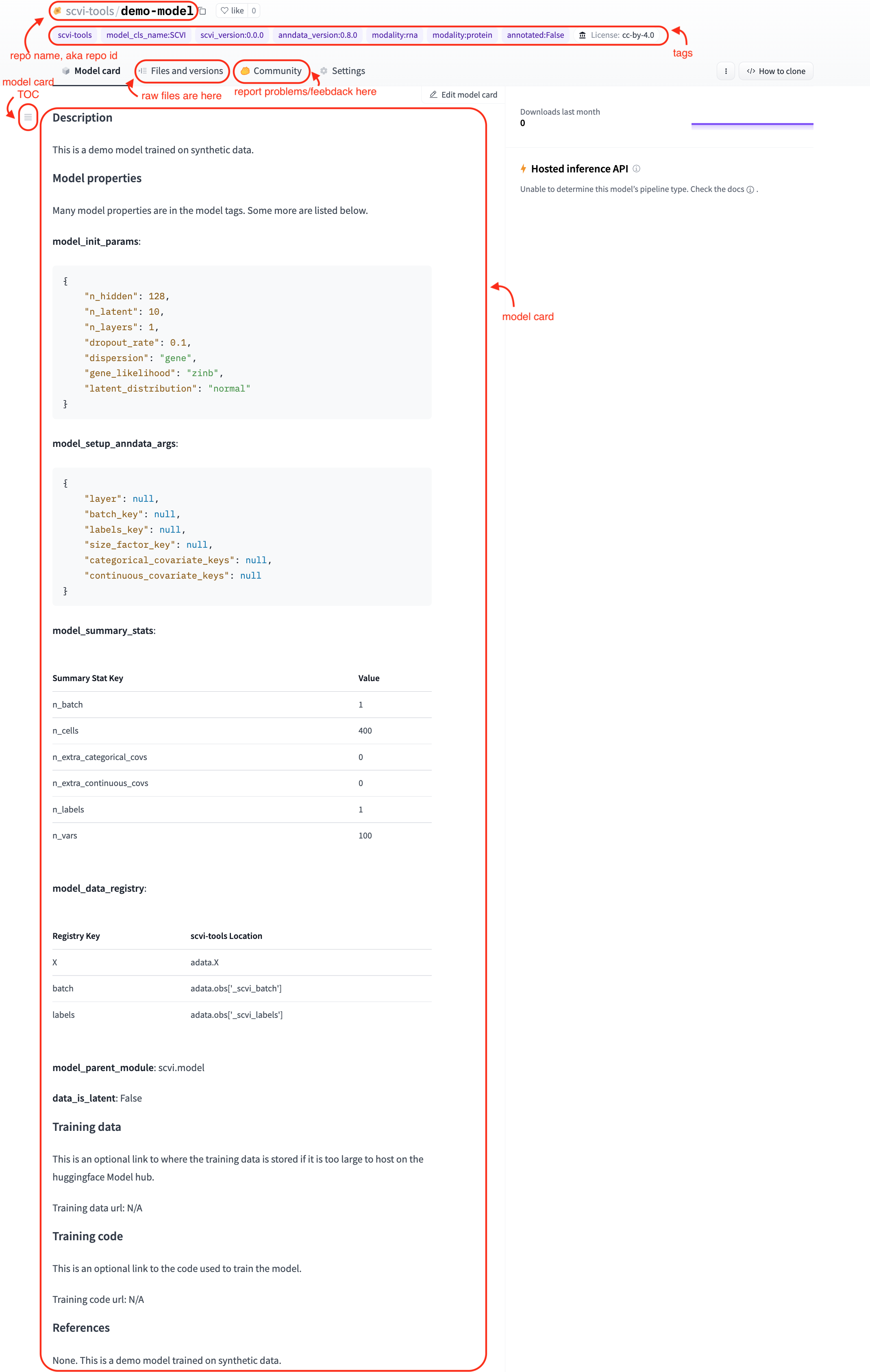
Most of our model tags and Model Card sections are self-explanatory. Nonetheless, below we provide a brief description for each of them.
Tags:
License
Library name. “scvi-tools” for all scvi-tools models.
Model class name. The name of the scvi-tools model class that was used to train the model. For example, “SCVI” for a
scvi.model.SCVImodel.scvi-tools version. The version of scvi-tools that was used to train the model.
anndata version. The version of anndata that was used when training the model.
Modalities. The modalities that were used to train the model. For example, “modality:rna” for a model trained on RNA-seq data only.
Tissues. The tissues present in the data that was used to train the model. For example, “tissue:skin”.
Annotated. Whether the data contains curated annotations (cell types).
Model Card sections:
Description. A brief description of the model.
Model init params. The parameters that were used to initialize the model, i.e, passed into the model’s
__init__method.Model setup_anndata args. The parameters that were used to call this model’s
setup_anndatamethod.Model summary stats. A table containing summary statistics for the anndata object registered for this model.
Model data registry. A table containing the data registry for the anndata object registered for this model.
Model parent module. The name of the scvi-tools module that contains the model class. For example “scvi.model” for a
scvi.model.SCVImodel.Data is minified. Whether the data is minified or not.
Training data. An optional url to where the training data is stored if it is too large to host on the Hugging Face Model hub. More on this in a future section.
Training code. An optional url to a script describing how the model was trained.
References
_scvi_required_metadata.json#
If you have been exploring the demo model, you might have noticed a file under “Files and versions” named _scvi_required_metadata.json. As its name implies, this file contains metadata that is required for scvi-tools to be able to accomplish certain tasks such as loading your model. As we will see in the scvi-hub upload tutorial, we provide utilities to auto-generate this file, much like we do for the Model Card.
You might notice that certain attributes in this file coincide with Model Card content/metadata. However, we chose to store these in a separate file (despite the minor duplication), so as to avoid building dependency on the Model Card. This way, you are free to have the Model Card content that you desire your users to see, all the while still being able to use scvi-tools to interact with your model.
Two things are important to keep in mind with respect to the required metadata file:
For the most part you don’t need to worry about this file. However, you should still know what is in it so that if you modify certain things, you update the metadata file accordingly. For instance, the metadata file currently includes the
training_data_url. So if you change where the training data is stored, you should update this field or else scvi-tools will fail to load the model/data.Other than cases such as the above, please do not tamper with this file nor remove it.
Glossary#
A vocabulary reference that you might find useful:
Hugging Face/HF: a suite of tools for building ML-based applications.
HF Hub: a platform for sharing/using ML-related products by the community, including pretrained models, datasets, and demo apps (called HF Spaces)
HF Model Hub: the HF Hub for pretained models
HF Hub Model: a pretrained model hosted on the HF Model Hub
Repository: a collection of files that are tracked by Git. You hear this in Github parlance, but it’s also used with HF, because as we saw earlier each HF Model is essentially a Git repository. So sometimes, you’ll hear people refer to a HF Hub Model as a repository or a Model repository.
scvi-tools: Y’all know and love it already 😊
scvi-hub:
a submodule of scvi-tools (
scvi.hub) that handles interaction with HFthis term also refers to the collection of pretrained scvi-tools models hosted on the HF Model Hub
Code overview#
Below we provide a brief overview of the main classes and functions that you will be interacting with. You can of course read more in our scvi-tools API docs.
scvi.hub.HubModel. This class represents a pretrained scvi-tools model on the HF Model Hub. For example the demo-model we saw earlier would be abstracted as a HubModel. You will mainly use this class to:Push a new model to the HF Model Hub.
Pull an existing model from the HF Model Hub.
Load the pretrained model into memory. This is done by invoking the
HubModel.modelproperty which will automatically load the model into memory if it is not already loaded. This will also load the data; see below for what that does.Load the data that was used to train the model into memory. This is done by invoking the
HubModel.adataproperty which will automatically load the data into memory if it is not already loaded. This will also download the data from the giventraining_data_urlif needed. We will learn more about large data handling in the scvi-hub upload tutorial.
scvi.hub.HubModelCardHelper. As its name indicates, this class helps in generating a Model Card that works for most scvi-tools models. You can do so by calling itsfrom_dirclass method which will automatically populate the Model Card with relevant information from the model and data objects, located at the given directory. You can also give it some more metadata that cannot be auto-inferred (such as license). The corresponding HF Model Card object is accessible via themodel_cardproperty.scvi.hub.HubMetadata. This class encapsulates the metadata that is present in the _scvi_required_metadata.json file. LikeHubModelCardHelper, it has afrom_dirclass method that can be used to auto-generate it using the model and data objects located at a given directory.
Download models#
Before we move on to downloading models, let’s first add the Python imports we need.
from scvi.hub import HubModel
Now, let’s use scvi-tools to download a model. We’ll use the demo-model we saw previously.
hmo = HubModel.pull_from_huggingface_hub(
repo_name="scvi-tools/test-scvi",
cache_dir=save_dir.name,
revision="main",
)
Notice the local directory property hmo.local_dir. This where Hugging Face caches the data it downloads. Hugging Face uses a heuristic to determine the location (more here). As we did above, you can override it by calling:
hmo = HubModel.pull_from_huggingface_hub(repo_name="scvi-tools/demo-model", cache_dir="/path/to/cache/dir")
Next we can see the metadata and the model card. We also see that the model and data are not yet loaded into memory. We can load them by calling hmo.model, and hmo.adata respectively.
hmo.model
INFO Loading model...
INFO File
/tmp/tmp8brcj8up/models--scvi-tools--test-scvi/snapshots/84c3a7071ef39e641a03698e52f8b6e7e44fa2e4/model.pt
already downloaded
SCVI model with the following parameters: n_hidden: 128, n_latent: 10, n_layers: 1, dropout_rate: 0.1, dispersion: gene, gene_likelihood: zinb, latent_distribution: normal. Training status: Trained Model's adata is minified?: False
hmo.adata
INFO Reading adata...
INFO No data found on disk. Skipping...
AnnData object with n_obs × n_vars = 400 × 100
obs: 'batch', 'labels', '_scvi_batch', '_scvi_labels'
uns: '_scvi_manager_uuid', '_scvi_uuid', 'protein_names'
obsm: 'accessibility', 'protein_expression'
Note
It is always possible to use another dataset than the data associated with the model. You may do so by calling HubModel.load_model and providing the adata parameter. This workflow follows the same rules as in regular scvi-tools – your data is validated against the data the model was trained on.
Large training data#
Depending on the size of the dataset used to train the model, there can be different scenarios, described below.
The model and its full training data are stored in the HF Hub Model.
👉 In this case:
hmo.modelandhmo.load_model()will load the model using the full training data.
hmo.adataandhmo.read_adata()will load the full training data.
hmo.large_training_adataandhmo.read_large_training_adata()will no-op (and return None) since there is no link to the full training data.The model and a minification of the training data are stored in the HF Hub Model. Optionally, there may be a link to the full (i.e., non-minified) training data in the Hub Model metadata.
👉 In this case:
hmo.modelandhmo.load_model()will load the model using the minified data.
hmo.adataandhmo.read_adata()will load the minified data.
hmo.large_training_adataandhmo.read_large_training_adata()will download and load into memory the full training data if there is a link to it, else it will no-op (and return None).Only the model is stored in the HF Hub Model. There should be a link to the full training data in the Hub Model metadata.
👉 In this case:
hmo.modelandhmo.load_model()will download the full training data and load the model using the latter.
hmo.adataandhmo.read_adata()will no-op (and return None).
hmo.large_training_adataandhmo.read_large_training_adata()will download and load into memory the full training data.
Versioning#
HF uses Git to seamlessly handle versioning. So if you want to download a specific version of a model, you can do so by specifying the commit hash. You can pass this into the pull function via the revision argument.
Important
Though the “revision” argument is not required to allow flexibility, we highly recommend that you always provide it. This is because files might get updated on the HF Hub Model (e.g., by other collaborators or model maintainers), and if you don’t specify a revision, you might end up with a different version of the model than you intended.
Next steps#
So what’s next? Well you can now use the model to do whatever you want, as if you had trained a model yourself using the scvi-tools API. For example, you can use the model to generate latent representations of your data, or to perform differential expression analysis. Additionally, for certain models, you can fine-tune them on your own data.
Please browse the scvi-tools tutorials for explicit examples using scvi-hub in workflows.