Benchmarking the scANVI fix#
As of the scvi-tools 1.1.0 release, we have included a critical bug fix for scANVI, which is used for semi-supervised modeling of single-cell transcriptomics data. In previous versions, the classifier portion of the model incorrectly treated logits outputs as probabilities, generally leading to the following consequences:
Increased number of training epochs required for the convergence of the classification loss
Accuracy, F1 score, and calibration error indicative of a poorly performing classifier
Inferior performance in label transferring to query data
Latent space with conservation of cell-type variability
Users may refer to the corresponding pull request for more details about the fix.
In this tutorial, we use the data and preprocessing steps in Atlas-level integration of lung data, while comparing the previous and fixed models. In addition to these, we include in our comparison a version of the fixed model with a simpler, linear classifier. We hypothesize that the previous (more complex) MLP classifier was necessary since the model specification was incorrect.
Imports and downloading data#
Note
Running the following cell will install tutorial dependencies on Google Colab only. It will have no effect on environments other than Google Colab.
!pip install --quiet scvi-colab
from scvi_colab import install
install()
import os
import tempfile
import matplotlib.pyplot as plt
import numpy as np
import scanpy as sc
import scvi
import seaborn as sns
import torch
from scib_metrics.benchmark import Benchmarker
scvi.settings.seed = 0
print("Last run with scvi-tools version", scvi.__version__)
Last run with scvi-tools version 1.4.2
Note
You can modify save_dir below to change where the data files for this tutorial are saved.
sc.set_figure_params(figsize=(6, 6), frameon=False)
sns.set_theme()
torch.set_float32_matmul_precision("high")
save_dir = tempfile.TemporaryDirectory()
%config InlineBackend.print_figure_kwargs={"facecolor": "w"}
%config InlineBackend.figure_format="retina"
Note that this dataset has the counts already separated in a layer. Here, adata.X contains log transformed scran normalized expression.
adata_path = os.path.join(save_dir.name, "lung_atlas.h5ad")
adata = sc.read(
adata_path,
backup_url="https://exampledata.scverse.org/scvi-tools/lung_atlas_preprocessed.h5ad",
)
adata
AnnData object with n_obs × n_vars = 32472 × 2000
obs: 'dataset', 'location', 'nGene', 'nUMI', 'patientGroup', 'percent.mito', 'protocol', 'sanger_type', 'size_factors', 'sampling_method', 'batch', 'cell_type', 'donor'
var: 'highly_variable', 'highly_variable_rank', 'means', 'variances', 'variances_norm', 'highly_variable_nbatches'
uns: 'hvg'
layers: 'counts'
Preprocessing data#
Note
For general pre-processing for various datatypes used by scvi-tools models, see the preprocessing tutorial.
This dataset was already processed as described in the scIB manuscript. Generally, models in scvi-tools expect data that has been filtered/aggregated in the same fashion as one would do with Scanpy/Seurat.
Another important thing to keep in mind is highly-variable gene selection. While scVI and scANVI both accomodate using all genes in terms of runtime, we usually recommend filtering genes for best integration performance. This will, among other things, remove batch-specific variation due to batch-specific gene expression.
We perform this gene selection using the Scanpy pipeline while keeping the full dimension normalized data in the adata.raw object. We obtain variable genes from each dataset and take their intersections.
adata.raw = adata # keep full dimension safe
print(f"Number of genes before HVG selection: {adata.n_vars}")
sc.pp.highly_variable_genes(
adata,
flavor="seurat_v3",
n_top_genes=2000,
layer="counts",
batch_key="batch",
subset=True,
)
print(f"Number of genes after HVG selection: {adata.n_vars}")
Number of genes before HVG selection: 2000
Number of genes after HVG selection: 2000
Important
We see a warning about the data not containing counts. This is due to some of the samples in this dataset containing SoupX-corrected counts. scvi-tools models will run for non-negative real-valued data, but we strongly suggest checking that these possibly non-count values are intended to represent pseudocounts, and not some other normalized data, in which the variance/covariance structure of the data has changed dramatically.
Model setup and training scVI#
As a first step, we assume that the data is completely unlabelled and we wish to find common axes of variation between the two datasets. There are many methods available in scanpy for this purpose (BBKNN, Scanorama, etc.). In this notebook we present scVI. To run scVI, we simply need to:
Register the AnnData object with the correct key to identify the sample and the layer key with the count data.
Create an SCVI model object.
We note that these parameters are non-default; however, they have been verified to generally work well in the integration task.
scvi.model.SCVI.setup_anndata(adata, layer="counts", batch_key="batch")
scvi_model = scvi.model.SCVI(adata, n_layers=2, n_latent=30, gene_likelihood="nb")
scvi_model.train(max_epochs=300)
Training models for comparison#
Now that we have our pre-trained scVI model available, we can initialize our three comparison scANVI models:
Pre-fix model: Users may replicate the (buggy) behavior in previous releases by passing in
classifier_parameters={"logits": False}to theSCANVIconstructorFixed model: With
scvi-tools>=1.1.0, the fix is included as the defaultFixed model with linear classifier: By passing in
linear_classifier=True, we replace the MLP classifier with a single linear layer
Note that we keep all other parameters the same between the models (e.g. max_epochs) so that the comparison is fair.
model_no_fix = scvi.model.SCANVI.from_scvi_model(
scvi_model,
adata=adata,
labels_key="cell_type",
unlabeled_category="Unknown",
classifier_parameters={"logits": False},
)
model_no_fix.train(max_epochs=100, check_val_every_n_epoch=1)
INFO Training for 100 epochs.
model_fix = scvi.model.SCANVI.from_scvi_model(
scvi_model,
adata=adata,
labels_key="cell_type",
unlabeled_category="Unknown",
)
model_fix.train(max_epochs=100, check_val_every_n_epoch=1)
INFO Training for 100 epochs.
model_fix_linear = scvi.model.SCANVI.from_scvi_model(
scvi_model,
adata=adata,
labels_key="cell_type",
unlabeled_category="Unknown",
linear_classifier=True,
)
model_fix_linear.train(max_epochs=100, check_val_every_n_epoch=1)
INFO Training for 100 epochs.
Plotting loss curves#
In order to compare the three models, we start by plotting three metrics:
Classification loss: The loss value directly optimized for cell-type prediction in the scANVI classifier, i.e., the cross-entropy loss
Expected calibration error: A measure of how well the classifier is calibrated, i.e., is the classifier confident when it is correct and unconfident when it is incorrect?
Accuracy: The proportion of labeled observations whose cell-type label the classifier is able to correctly predict
In this case, we’re not as interested in whether the models convergence at the end of 100 epochs as much as how stable the curves seem and whether the validation metrics diverge. The following function will plot the values of these metrics across training epochs for each of the models.
def plot_classification_metrics(
model_no_fix: scvi.model.SCANVI,
model_fix: scvi.model.SCANVI,
model_fix_linear: scvi.model.SCANVI,
):
fig, axes = plt.subplots(nrows=3, ncols=3, figsize=(10.5, 7), sharey=False, sharex=True)
def plot_metric(ax, metric, model, title, ylim, lw=1.25):
ax.plot(
model.history[f"train_{metric}"],
label="train",
color="darkgreen",
linewidth=lw,
)
ax.plot(
model.history[f"validation_{metric}"],
label="validation",
color="firebrick",
linewidth=lw,
)
ax.set_ylim(ylim)
ax.legend()
ax.set_title(title)
metrics = ["classification_loss", "calibration_error", "accuracy"]
ylims = [(-0.1, 2.3), (-0.01, 0.18), (0.8, 1.0)]
models = [model_no_fix, model_fix, model_fix_linear]
model_names = ["No fix", "Fix", "Fix linear"]
for i, (metric, ylim) in enumerate(zip(metrics, ylims, strict=False)):
for j, (model, model_name) in enumerate(zip(models, model_names, strict=False)):
plot_metric(axes[i, j], metric, model, model_name, ylim=ylim)
fig.text(-0.01, 0.8, "Classification loss", va="center", rotation="vertical")
fig.text(-0.01, 0.5, "Calibration error", va="center", rotation="vertical")
fig.text(-0.01, 0.2, "Accuracy", va="center", rotation="vertical")
fig.text(0.5, -0.01, "Epoch", ha="center")
fig.tight_layout()
plot_classification_metrics(model_no_fix, model_fix, model_fix_linear)
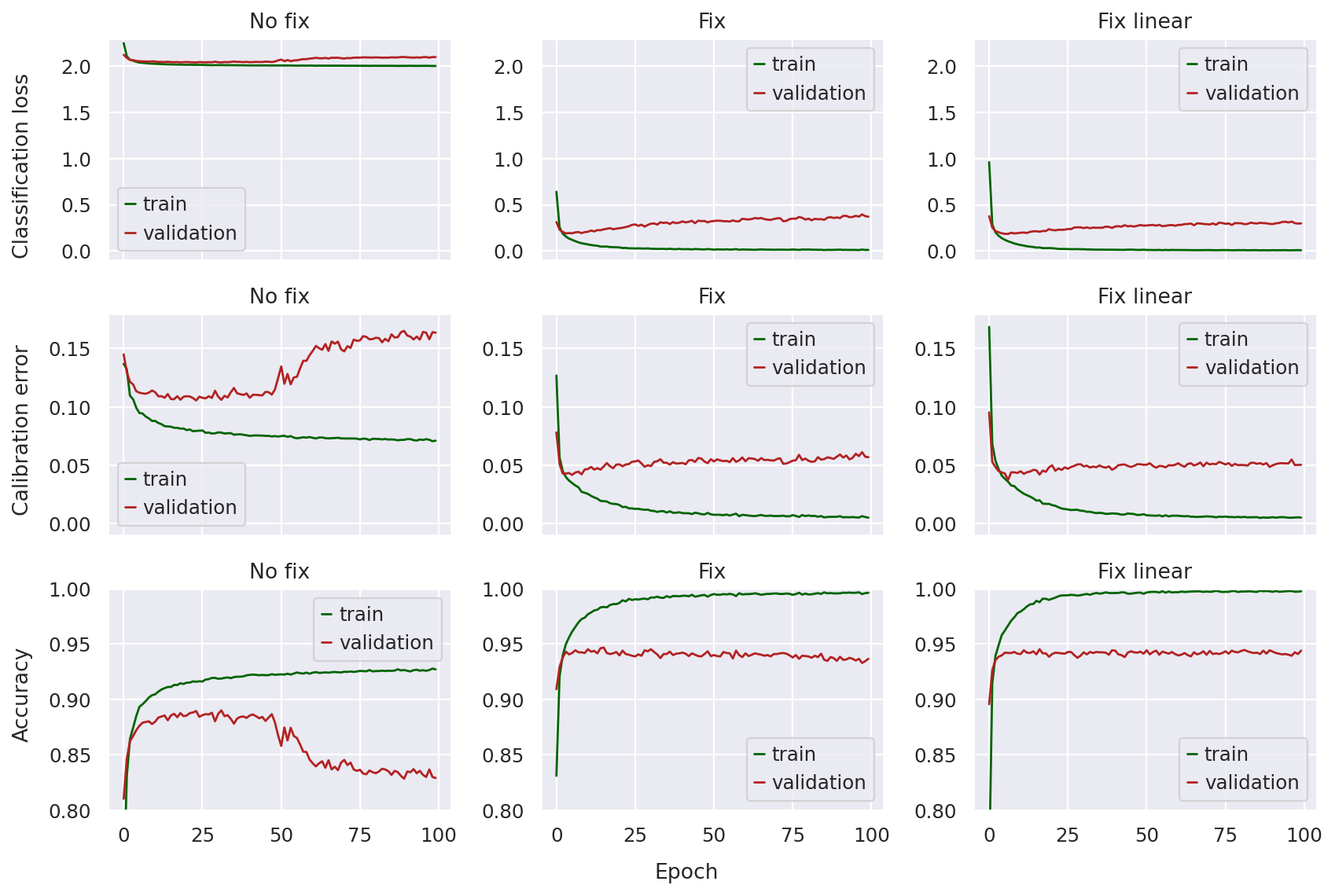
Looking at the top row, we can immediately notice that the pre-fix model has a classification loss a magnitude larger than the other two (smaller is better). The curves don’t seem as dramatic since the validation loss does not seem to diverge that much (i.e. the validation loss stays fairly close to the training loss), so we might incorrectly assume that the no fix model classifier is training with stability.
However, once we take a look at the calibration error and accuracy, the problem is clear: in later epochs, these metrics increase (in the case of calibration error) or decrease (in the case of accuracy) sharply, indicating something wrong with model training.
This is not the case for the fixed models, where the classification loss is much lower throughout training, and both the calibration error and accuracy curves are much more stable. There does not seem to be too much of a difference between the fixed and fixed-linear model other than the linear one seeming a bit more “smooth”.
Plotting confusion matrices#
Next, we plot confusion matrices for the validation observations. We are interested in just the validation split since the classifier will tend to overfit on the training set, so we’d like to see how it performs on unseen data.
def plot_confusion_matrices(
model_no_fix: scvi.model.SCANVI,
model_fix: scvi.model.SCANVI,
model_fix_linear: scvi.model.SCANVI,
subset: str | None = None,
prediction_key: str = "_prediction",
labels_key: str = "cell_type",
):
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(18, 6.375), sharey=False, sharex=False)
def plot_confusion_matrix(ax, model, title, subset):
adata = model.adata
adata.obs[prediction_key] = model.predict()
if subset == "validation":
adata = adata[model.validation_indices].copy()
elif subset == "train":
adata = adata[model.train_indices].copy()
df = adata.obs.groupby([labels_key, prediction_key]).size().unstack(fill_value=0)
conf_mat = df / df.sum(axis=1).values[:, np.newaxis]
_ = ax.pcolor(conf_mat, cmap="cividis", vmin=0, vmax=1)
_ = ax.set_xticks(np.arange(0.5, len(df.columns), 1), df.columns, rotation=90)
_ = ax.set_yticks(np.arange(0.5, len(df.index), 1), df.index)
ax.set_title(title)
models = [model_no_fix, model_fix, model_fix_linear]
model_names = ["No fix", "Fix", "Fix linear"]
for model, model_name, ax in zip(models, model_names, axes, strict=False):
plot_confusion_matrix(ax, model, model_name, subset)
fig.text(0.0, 0.5, "Observed", va="center", rotation="vertical")
fig.text(0.5, 0.0, "Predicted", ha="center")
fig.tight_layout()
plot_confusion_matrices(model_no_fix, model_fix, model_fix_linear, subset="validation")
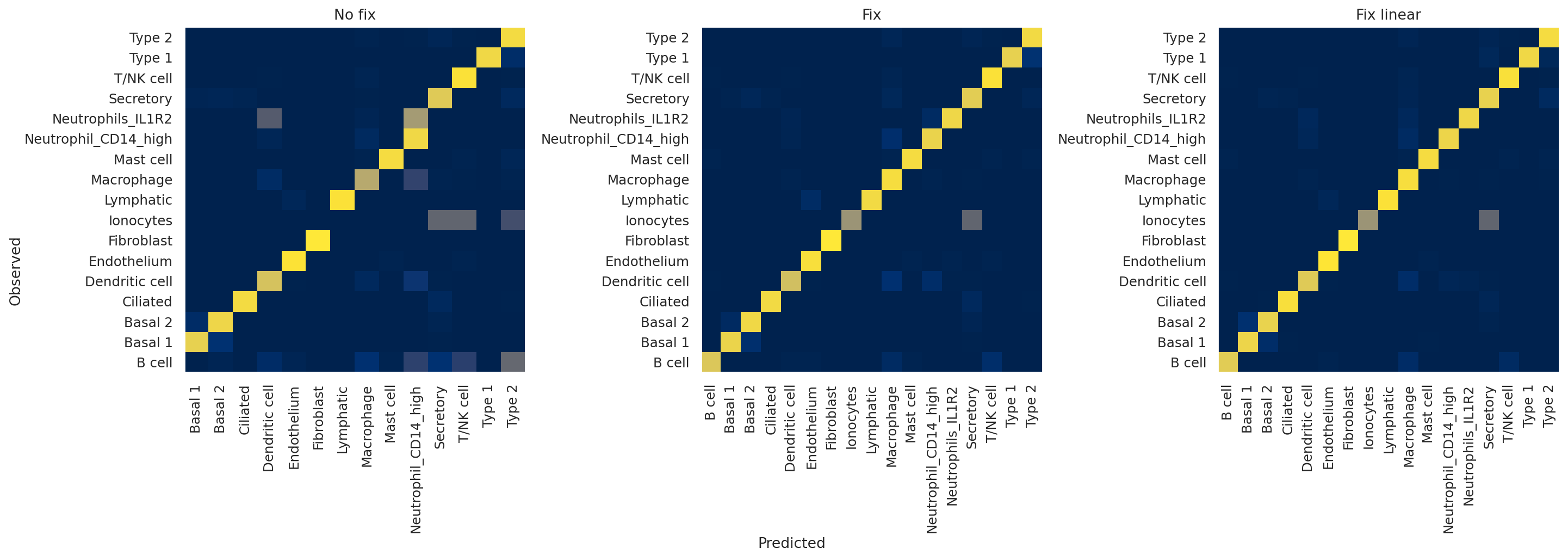
The x-axis indicates predicted labels, the y-axis observed labels, and the intensity of each square indicates the overlap between these two. In other words, if the square corresponding to “B cell observed” and “B cell predicted” has a value of 1 (bright yellow), this means that 100% of cells that the model classified as B cells have a ground truth label of B cells, and vice versa. A perfect classifier, then, would only have values of 1 along the diagonal and 0 elsewhere.
Qualitatively, we can appreciate that the no fix model performs very poorly, with, for example, almost no B cells being predicted by the model. On the other hand, the two fixed models seem to be performing well, with only slight differences between the two.
Visualizing the embeddings#
Visualizing the embeddings using UMAPS can be another useful qualitative check for evaluating how informative the model embeddings are of cell-type variability as well as batch integration performance.
def plot_latent_umaps(
model_no_fix: scvi.model.SCANVI,
model_fix: scvi.model.SCANVI,
model_fix_linear: scvi.model.SCANVI,
color: list | str | None = None,
subset: str | None = None,
latent_key: str = "_latent",
):
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(11, 3), sharey=False, sharex=False)
def plot_latent_umap(ax, model, title, subset, legend_loc):
adata = model.adata
adata.obsm[latent_key] = model.get_latent_representation()
sc.pp.neighbors(adata, use_rep=latent_key)
if subset == "validation":
adata = model.adata[model.validation_indices].copy()
elif subset == "train":
adata = model.adata[model.train_indices].copy()
sc.tl.umap(adata, min_dist=0.3)
sc.pl.umap(
adata,
color=color,
frameon=False,
ncols=1,
ax=ax,
show=False,
legend_loc=legend_loc,
)
ax.set_title(title)
models = [model_no_fix, model_fix, model_fix_linear]
model_names = ["No fix", "Fix", "Fix linear"]
legend_loc = ["none", "none", "right margin"]
for model, model_name, ax, leg_loc in zip(models, model_names, axes, legend_loc, strict=False):
plot_latent_umap(ax, model, model_name, subset, leg_loc)
fig.text(0.0, 0.5, "UMAP_2", va="center", rotation="vertical")
fig.text(0.5, 0.0, "UMAP_1", ha="center")
fig.tight_layout()
plot_latent_umaps(model_no_fix, model_fix, model_fix_linear, color="cell_type")
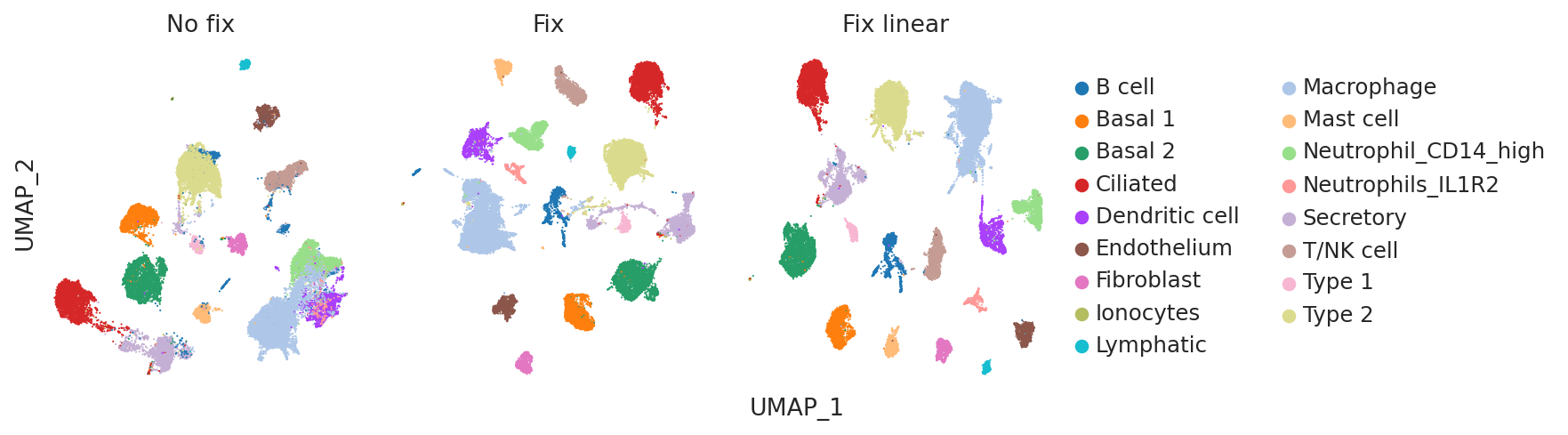
Once again, visually inspecting the embeddings confirms that the no fix model suffers from poor cell type identification (e.g. B cells and Type 2 cells are poorly separated).
Comparing integration metrics#
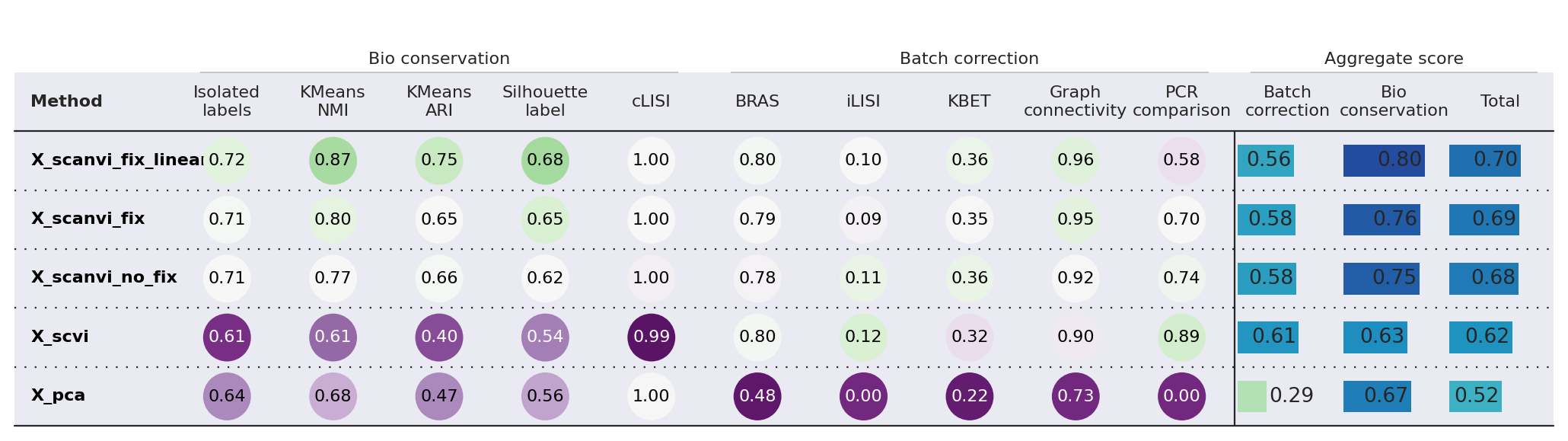
Finally, we can compute various integration metrics on the model embeddings to quantitatively assess their performance on biological conservation and batch integration. We rely on the scib-metrics package for this. We start by computing the latent representations of each of these models.
X_SCVI_KEY = "X_scvi"
X_SCANVI_NO_FIX_KEY = "X_scanvi_no_fix"
X_SCANVI_FIX_KEY = "X_scanvi_fix"
X_SCANVI_FIX_LINEAR_KEY = "X_scanvi_fix_linear"
adata.obsm[X_SCVI_KEY] = scvi_model.get_latent_representation()
adata.obsm[X_SCANVI_NO_FIX_KEY] = model_no_fix.get_latent_representation()
adata.obsm[X_SCANVI_FIX_KEY] = model_fix.get_latent_representation()
adata.obsm[X_SCANVI_FIX_LINEAR_KEY] = model_fix_linear.get_latent_representation()
bm = Benchmarker(
adata,
batch_key="batch",
label_key="cell_type",
embedding_obsm_keys=[
"X_pca",
X_SCVI_KEY,
X_SCANVI_NO_FIX_KEY,
X_SCANVI_FIX_KEY,
X_SCANVI_FIX_LINEAR_KEY,
],
n_jobs=-1,
)
bm.benchmark()
bm.plot_results_table(min_max_scale=False)
<plottable.table.Table at 0x713ac6e8b4d0>
While batch integration performance seems to degrade slightly from the pre-fix to fixed models, the difference is very small compared to the increased performance in bio-conservation. Particularly, we note a noticeable increase with using the linear classifier.