Quick start tutorial for CytoVI#
In this tutorial, we go through the steps of training CytoVI, a deep generative model that leverages antibody-based single-cell profiles to learn a biologically meaningful latent representation of each cell. CytoVI is designed for protein expression measurements (from flow cytometry, mass cytometry or CITE-seq data) and captures both technical and biological variation, enabling the generation of denoised marker intensities and interpretable low-dimensional embeddings.
In this tutorial, we go through the steps of training a CytoVI model using full spectrum cytometry data of peripheral blood mononuclear cells (PBMCs). We will analyze two repeated measurements of cryopreserved PBMCs from the same biological donor that were thawed and analyzed on two consecutive days (and thereby only differ in technical variation). We will demonstrate how CytoVI yields a joint cell state representation across these two measurements and effectively mitigates technical variation. We will then utilize this shared cell representation to annotate the immune subsets present in the PBMCs and quantify their abundance.
Plan for this tutorial:
Loading the data
Preprocessing the data and quality control
Training a CytoVI model
Visualizing and clustering the CytoVI latent space
Quantifying the abundance of immune cells present in the PBMCs
# Install from GitHub for now
!pip install --quiet scvi-colab
from scvi_colab import install
install()
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager, possibly rendering your system unusable. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv. Use the --root-user-action option if you know what you are doing and want to suppress this warning.
[notice] A new release of pip is available: 25.0.1 -> 26.1.2
[notice] To update, run: pip install --upgrade pip
import os
import random
import tempfile
import matplotlib.pyplot as plt # type: ignore
import numpy as np # type: ignore
import requests
import scanpy as sc # type: ignore
import scvi
import torch # type: ignore
from rich import print # type: ignore
from scvi.external import cytovi # type: ignore
os.environ["SCIPY_ARRAY_API"] = "1"
sc.set_figure_params(figsize=(4, 4))
scvi.settings.seed = 0
random.seed(42)
np.random.seed(42)
torch.manual_seed(42)
print("Last run with scvi-tools version:", scvi.__version__)
Last run with scvi-tools version: 1.5.0
Loading the data#
For this tutorial we will use full spectrum cytometry data of a single antibody-panel targeting 35 protein parameters and additional morphological features for FSC and SSC from the SARS-CoV-2 vaccine study from Nuñez, Schmid & Power et al. 2023 (Nature Immunology, https://doi.org/10.1038/s41590-023-01499-w). We will download a subset of the data comprising one donor that was measured in two different batches and thus served as a internal batch normalization control of the original study. Importantly, these data have already been corrected for fluorescent spillover and live single cells were exported.
temp_dir_obj = tempfile.TemporaryDirectory()
data_dir = temp_dir_obj.name
urls = [
"https://exampledata.scverse.org/scvi-tools/Nunez_PBMCs_batch1.fcs",
"https://exampledata.scverse.org/scvi-tools/Nunez_PBMCs_batch2.fcs",
]
downloaded_files = []
for url in urls:
response = requests.get(url)
response.raise_for_status()
cd = response.headers.get("Content-Disposition", "")
if "filename=" in cd:
filename = cd.split("filename=")[1].strip("\"'")
else:
filename = os.path.basename(url)
file_path = os.path.join(data_dir, filename)
with open(file_path, "wb") as f:
f.write(response.content)
downloaded_files.append(file_path)
downloaded_files
['/tmp/tmpftcpx0al/Nunez_PBMCs_batch1.fcs',
'/tmp/tmpftcpx0al/Nunez_PBMCs_batch2.fcs']
We will read the fcs files and store the cytometry data as an AnnData object, similarly as common practice in scRNAseq and spatial transcriptomics analyses. If you are unfamilliar with AnnData, you can get a quick start here: https://anndata.readthedocs.io/en/latest/tutorials/notebooks/getting-started.html.
When reading the fcs files we will omit variables that are not informative for downstream processing remove_markers=['Time', 'LD', '-']. By default we store the raw protein expression in adata.X and adata.layers['raw'].
adata_batch1 = cytovi.read_fcs(downloaded_files[0], remove_markers=["Time", "LD", "-"])
adata_batch2 = cytovi.read_fcs(downloaded_files[1], remove_markers=["Time", "LD", "-"])
adata_batch1
AnnData object with n_obs × n_vars = 100000 × 41
obs: 'filename', 'sample_id'
layers: 'raw'
Preprocessing the data and quality control#
Before training CytoVI, we need to transform and normalize the cytometry data to make it more suitable for modeling.
Full spectrum cytometry produces fluorescence intensities that span several orders of magnitude. Because antibody-based single-cell measurements are relative by nature, preprocessing of the data is commonly performed before visualization or modeling. Cytometry data are typically transformed using functions like the hyperbolic arcsin, logicle, or biexponential to compress dynamic range and stabilize variance. This is usually followed by feature-wise scaling to ensure marker expression values are on comparable scales across all channels (more information can be found e.g. at Liechti et al. 2021, Nature Immunology, https://doi.org/10.1038/s41590-021-01006-z).
While CytoVI is capable of handling cytometry data preprocessed with any of these transformations, we here follow a simple two-step preprocessing strategy commonly used for cytometry:
Arcsinh transformation: This transformation is widely used in flow cytometry to stabilize variance and improve comparability across markers. It behaves linearly at low intensities and logarithmically at high intensities.
Feature-wise min-max scaling: After transformation, we rescale each marker (feature) individually to the [0, 1] range to account for differences in brightness across different fluorophores or differences in antibody affinities.
The choice of the arcsinh cofactor can influence the representation of the data. However, we have observed that CytoVI is relatively robust to the choice of the arcsinh cofactor and recommend a global_scaling_factor for all markers within an assay. The following arcsinh cofactors are commonly used as a starting point:
2000 for full spectrum cytometry (recommended here)
100 for conventional PMT-based flow cytometry
5 for mass cytometry (CyTOF and CITE-seq)
Users can specify feature-specific arcsinh cofactors by providing a scaling_dict to cytovi.transform_arcsinh(). By default cytovi.transform_arcsinh() will take the adata.layers['raw'] as input and write the arcsinh transformed expression into adata.layers['transformed'], while cytovi.scale will save the scaled expression in adata.layers['scaled'].
cytovi.transform_arcsinh(adata_batch1, global_scaling_factor=2000)
cytovi.scale(adata_batch1)
cytovi.transform_arcsinh(adata_batch2, global_scaling_factor=2000)
cytovi.scale(adata_batch2)
After processing each batch separately, we will combine the two batches using cytovi.merge_batches(). This will automatically register a batch_key in adata.obs. In case of differences in antibody panels between the batches, this function will automatically register a nan_layer that will handle the modeling of missing markers under the hood.
adata = cytovi.merge_batches([adata_batch1, adata_batch2])
adata
AnnData object with n_obs × n_vars = 200000 × 41
obs: 'filename', 'sample_id', 'batch'
layers: 'raw', 'transformed', 'scaled'
For the ease of handling the data, we will subsample the combined data to 10 000 cells per batch.
adata = cytovi.subsample(adata, n_obs=20000, groupby="batch")
adata
AnnData object with n_obs × n_vars = 20000 × 41
obs: 'filename', 'sample_id', 'batch'
layers: 'raw', 'transformed', 'scaled'
We can then inspect the scaled protein expression for all the markers in both batches using histograms or biaxial plots.
cytovi.plot_histogram(adata, marker="all", groupby="batch", layer_key="scaled")
cytovi.plot_biaxial(adata, marker_x="CD3", marker_y="CD4", color="batch", layer_key="scaled")
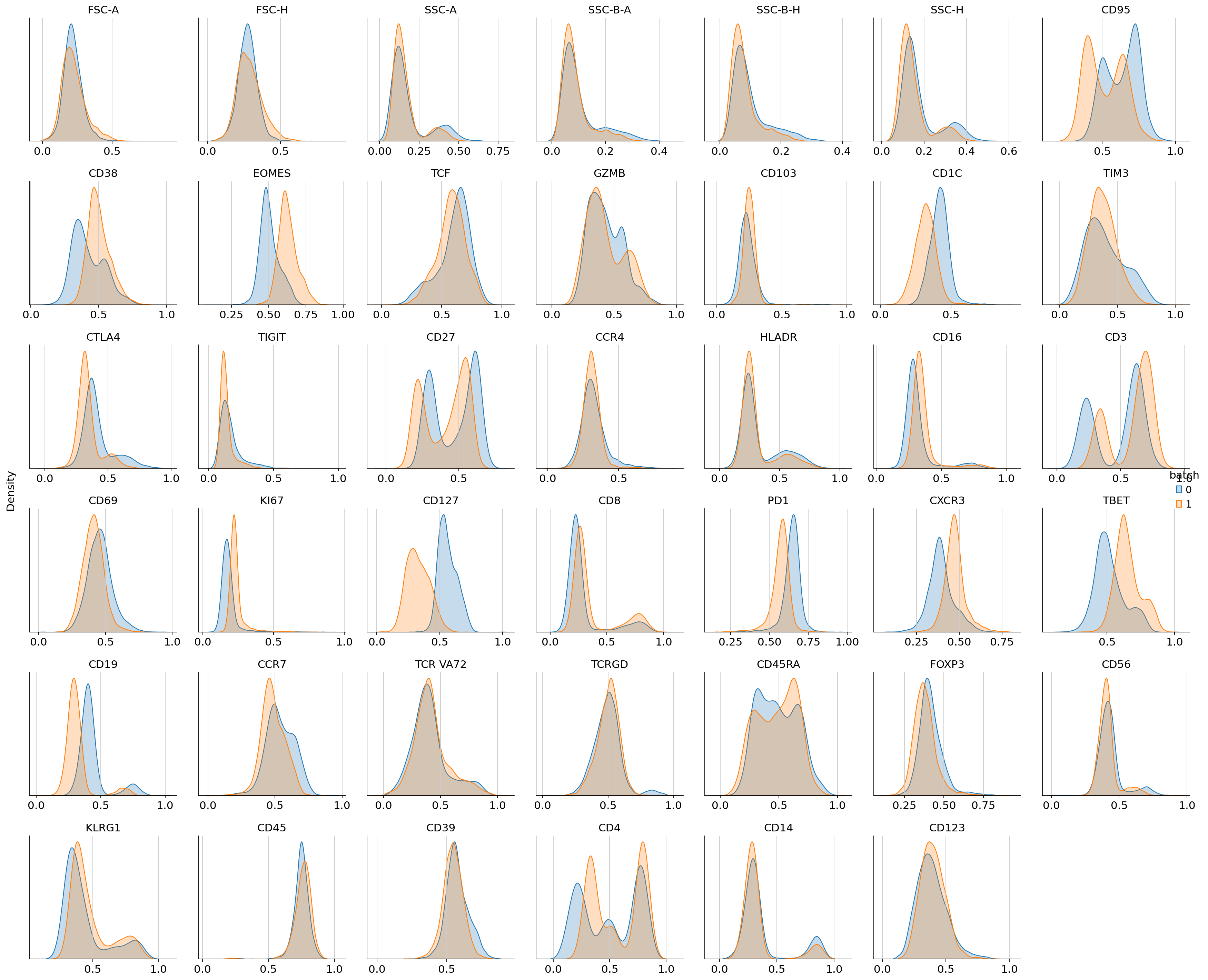
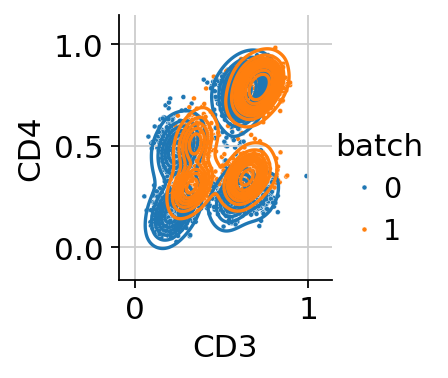
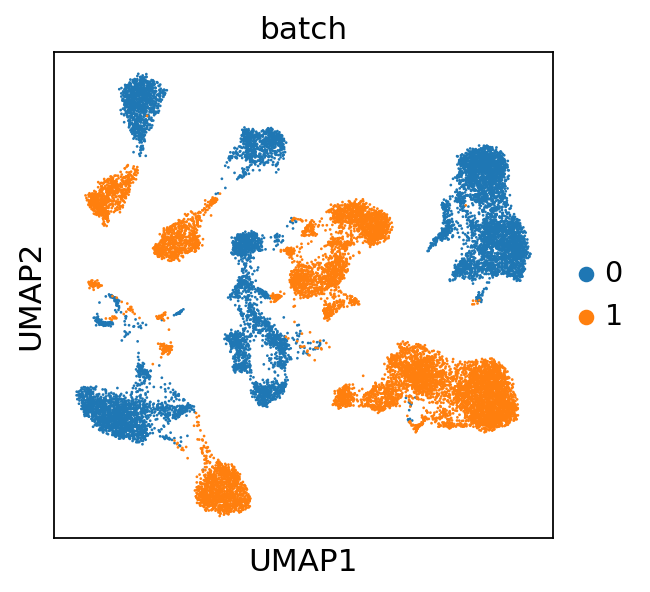
Inspection of these diagnostic plots indicates already the presence of technical variation between both batches. We will assess how this affects downstream analysis by computing a UMAP from the data without controlling for technical variation. Throughout this tutorial we will use the GPU-accellerated scanpy implementations to compute a nearest neighbor graph, UMAP and leiden clustering, which will lead to performance improvements when working with large datasets.
adata.X = adata.layers["scaled"]
sc.pp.neighbors(adata, use_rep="X", transformer="pynndescent")
sc.tl.umap(adata)
sc.pl.umap(adata, color="batch")
Training a CytoVI model#
We observe that the technical variability between the two different batches virtually obsecurs a joint downstream analysis. Therefore, we will next train a CytoVI model that explicitly controls for the technical variation between batches. For this we will register the scaled layer as the input expression to the model and the batch_key.
Optionally, the user can specify a label_key during AnnData setup, that can be used to weakly inform the model about a priori known cell type labels or we can specify a sample_key, indicating which cell came e.g. from which donor. Here we will showcase the simplest case of only specifying a batch_key.
cytovi.CYTOVI.setup_anndata(adata, layer="scaled", batch_key="batch")
model = cytovi.CYTOVI(adata)
model.train(n_epochs_kl_warmup=50)
Monitored metric elbo_validation did not improve in the last 30 records. Best score: -67.221. Signaling Trainer to stop.
We can print the model to get some important summary statistics about the CytoVI model.
model
CytoVI Model with the following params: n_hidden: 128, n_latent: 20, n_layers: 1, dropout_rate: 0.1, protein_likelihood: normal, latent_distribution: normal, MoG prior: True, n_labels 1, n_proteins: 41, Impute missing markers: False Training status: Trained
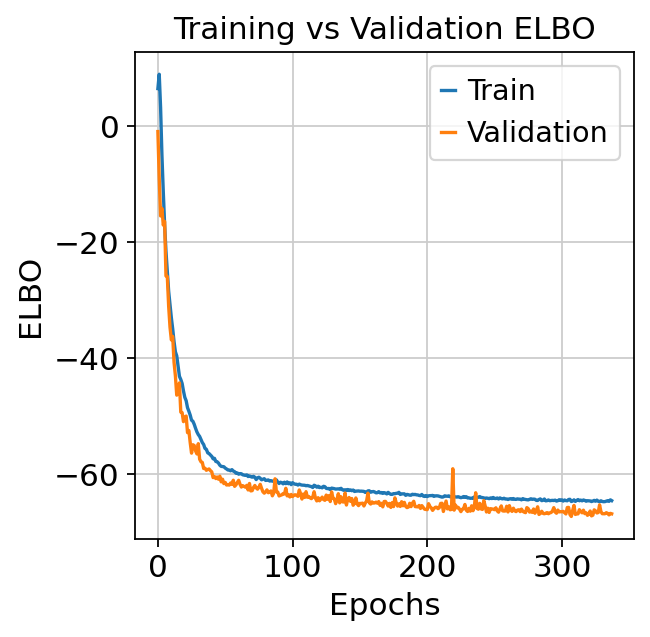
We can then assess the training dynamics of the model to see whether it has converged.
plt.plot(model.history["elbo_train"], label="Train")
plt.plot(model.history["elbo_validation"], label="Validation")
plt.xlabel("Epochs")
plt.ylabel("ELBO")
plt.legend()
plt.title("Training vs Validation ELBO")
plt.show()
Visualizing and clustering the CytoVI latent space#
Next we visualize the learnt latent representation of each cell that controls for the technical variability between batches. For this we access the latent space via get_latent_representation and compute an UMAP of the latent space.
adata.obsm["X_CytoVI"] = model.get_latent_representation()
sc.pp.neighbors(adata, use_rep="X_CytoVI", transformer="pynndescent")
sc.tl.umap(adata)
sc.pl.umap(adata, color="batch")
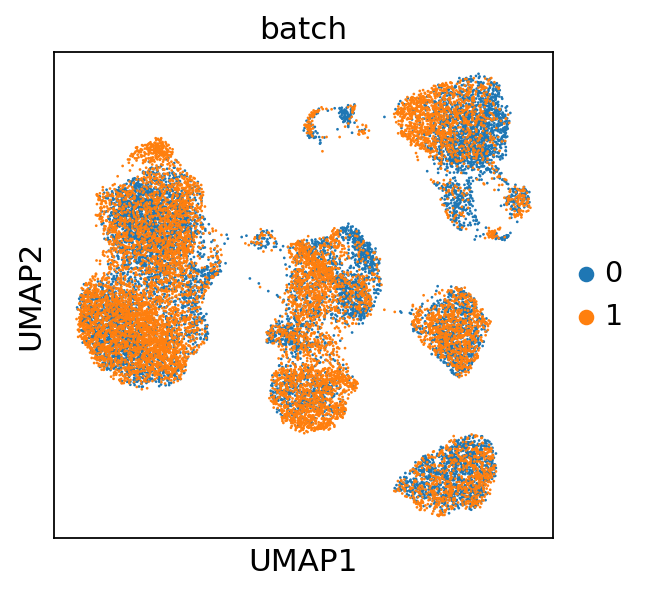
We observe that this latent representation of the cells virtually removed the technical variation between the two batches. Next, we will compute the denoised (and batch corrected) protein expression.
adata.layers["imputed"] = model.get_normalized_expression()
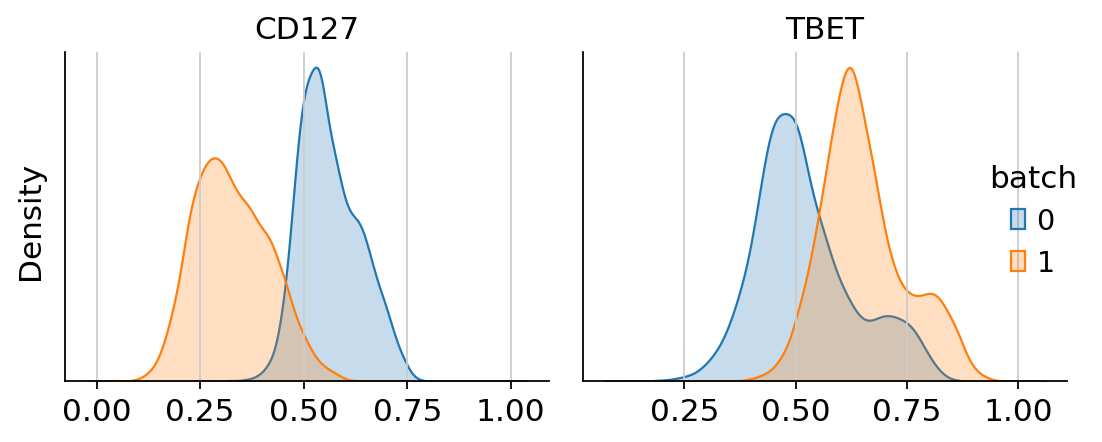
Next, we can visualize the uncorrected and corrected protein expression for two markers that showed a strong batch effect.
g = cytovi.plot_histogram(
adata, marker=["CD127", "TBET"], layer_key="scaled", groupby="batch", return_plot=True
)
g.fig.suptitle("Uncorrected expression", fontsize=16)
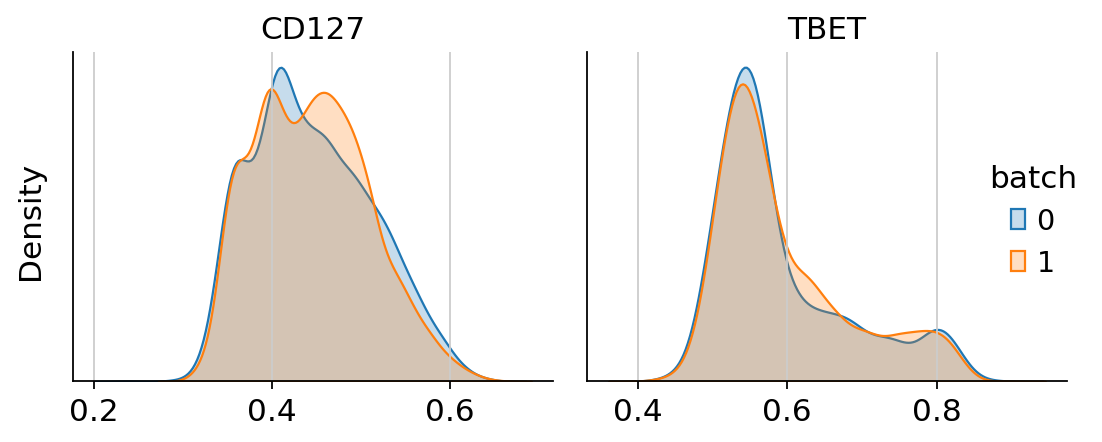
h = cytovi.plot_histogram(
adata, marker=["CD127", "TBET"], layer_key="imputed", groupby="batch", return_plot=True
)
h.fig.suptitle("Corrected expression", fontsize=16)
Text(0.5, 0.98, 'Corrected expression')
We see that CytoVI has mitigated the majority of technical variation between the two replicates. Next we visualize the denoised expression on the CytoVI latent space to explore the cell types present in the PBMCs.
sc.pl.umap(adata, color=adata.var_names, layer="imputed", ncols=5, cmap="mako")

To identify cell states and cell types we apply leiden clustering to the CytoVI latent space. If users are looking for more fine grained clusters, increasing the resolution parameter in sc.tl.leiden will yield a higher number of clusters.
sc.tl.leiden(adata, resolution=0.4, key_added="leiden_CytoVI", flavor="igraph")
sc.pl.umap(adata, color="leiden_CytoVI")
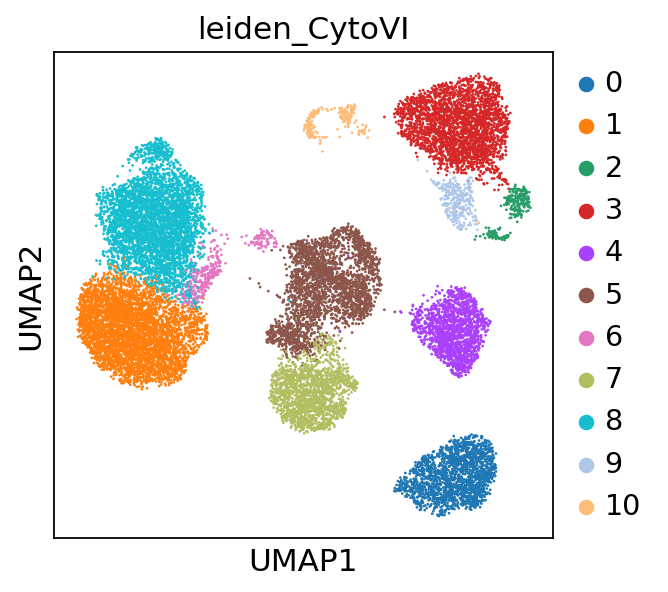
Quantifying the abundance of immune cells present in the PBMCs#
Next we will inspect the protein expression of each cluster of the latent space and use these expression profiles to annotate our clusters. Note: depending on the runtime environment used to execute the notebook, there may be slight adaptations needed for the manual annotations of the clusters.
sc.pl.matrixplot(
adata,
var_names=adata.var_names,
groupby="leiden_CytoVI",
layer="imputed",
dendrogram=True,
standard_scale="var",
cmap="mako",
)
WARNING: dendrogram data not found (using key=dendrogram_leiden_CytoVI). Running `sc.tl.dendrogram` with default parameters. For fine tuning it is recommended to run `sc.tl.dendrogram` independently.
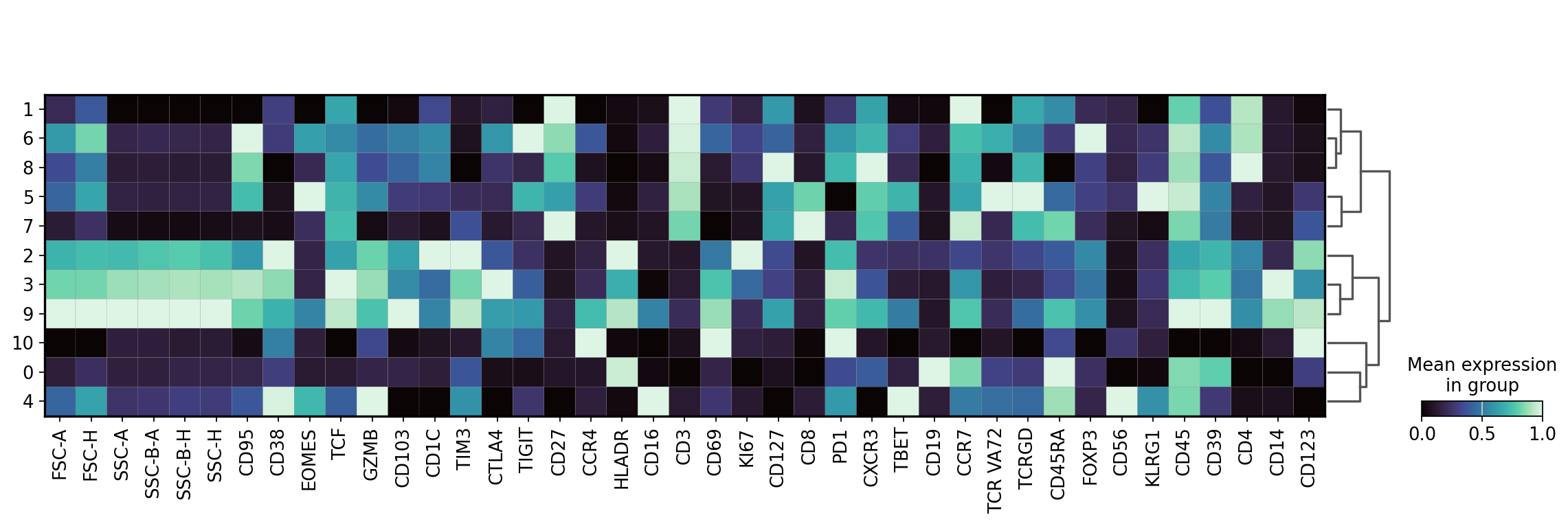
cell_annotation_dict = {
"0": "B cells",
"1": "Naive CD4 T cells",
"2": "Memory CD4 T cells",
"3": "Dendritic cells",
"4": "Classical monocytes",
"5": "Non-classical monocytes",
"6": "Natural killer cells",
"7": "Memory CD8 T cells",
"8": "Naive CD8 T cells",
"9": "Regulatory T cells",
"10": "Plasmacytoid dendritic cells",
}
adata.obs["cell_type"] = adata.obs["leiden_CytoVI"].map(cell_annotation_dict)
sc.pl.umap(adata, color="cell_type")
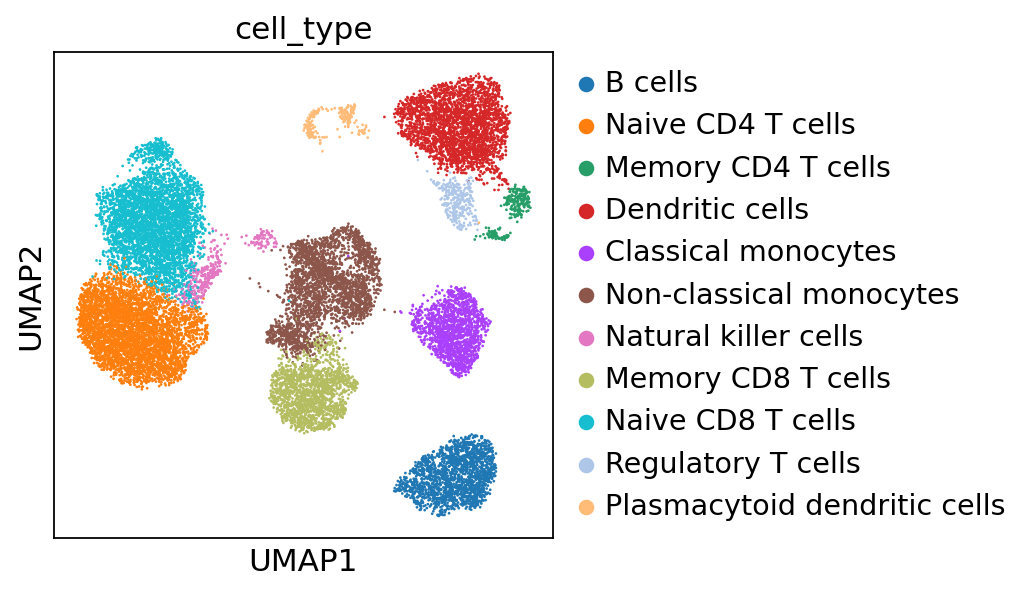
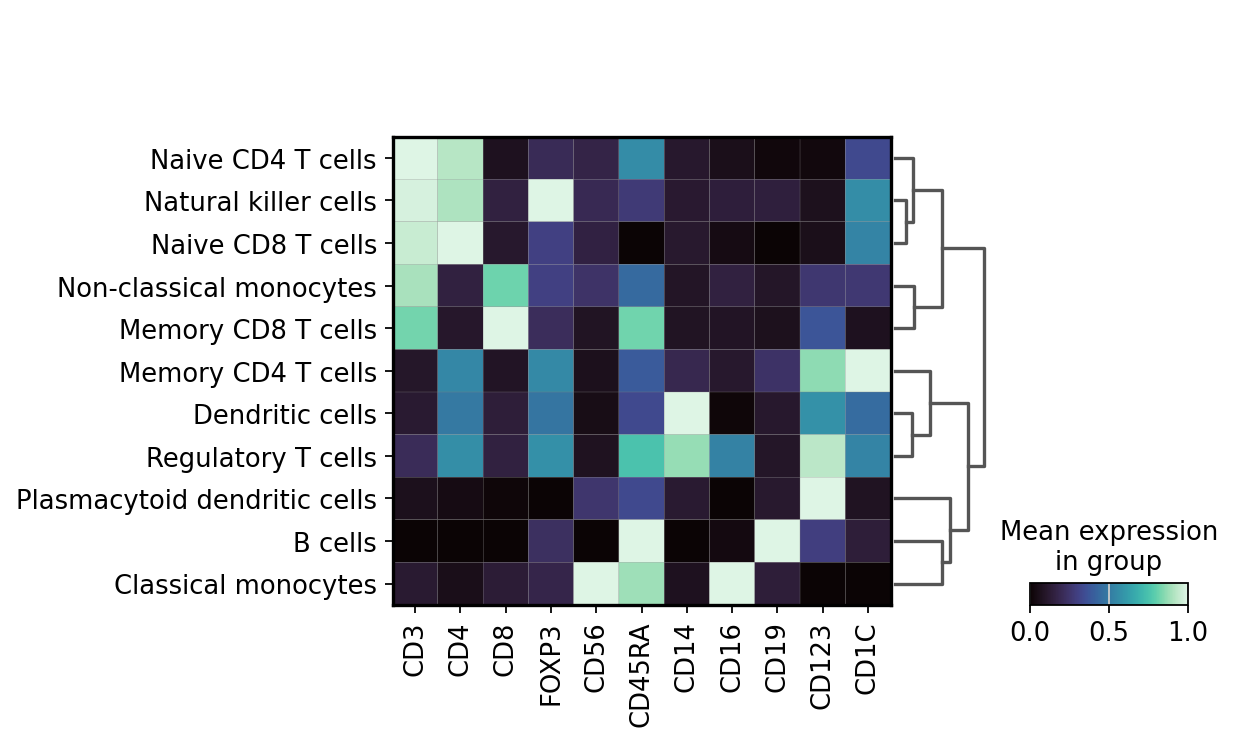
Now we can visualize the expression profiles of the annotated cell types using key markers.
markers_to_plot = [
"CD3",
"CD4",
"CD8",
"FOXP3",
"CD56",
"CD45RA",
"CD14",
"CD16",
"CD19",
"CD123",
"CD1C",
]
sc.pl.matrixplot(
adata,
var_names=markers_to_plot,
groupby="cell_type",
layer="imputed",
dendrogram=True,
standard_scale="var",
cmap="mako",
)
WARNING: dendrogram data not found (using key=dendrogram_cell_type). Running `sc.tl.dendrogram` with default parameters. For fine tuning it is recommended to run `sc.tl.dendrogram` independently.
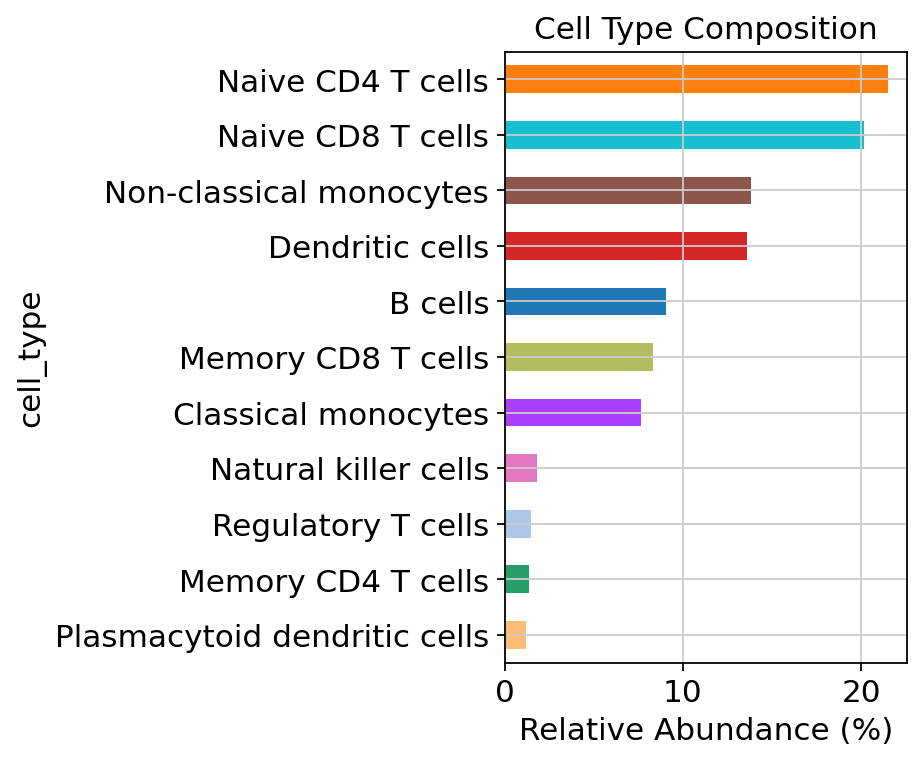
Next, we compute the relative frequencies of the cell types in the PBMCs.
cluster_counts = adata.obs["cell_type"].value_counts(normalize=True) * 100
cluster_counts = cluster_counts.sort_values(ascending=True)
cluster_counts
cell_type
Plasmacytoid dendritic cells 1.200
Memory CD4 T cells 1.355
Regulatory T cells 1.495
Natural killer cells 1.815
Classical monocytes 7.645
Memory CD8 T cells 8.335
B cells 9.040
Dendritic cells 13.605
Non-classical monocytes 13.820
Naive CD8 T cells 20.180
Naive CD4 T cells 21.510
Name: proportion, dtype: float64
celltype_colors = dict(
zip(adata.obs["cell_type"].cat.categories, adata.uns["cell_type_colors"], strict=False)
)
colors = [celltype_colors[ct] for ct in cluster_counts.index]
cluster_counts.plot(kind="barh", color=colors, figsize=(6, 5))
plt.xlabel("Relative Abundance (%)")
plt.title("Cell Type Composition")
plt.tight_layout()
plt.show()
We can now save the processed AnnData to disk or export the corrected fcs files using cytovi.write_fcs() for further downstream analyses. Here, we will export the AnnData as an h5ad file.
adata.write(f"{data_dir}/Nunez_et_al_PBMCs_annotated.h5ad")